Commit Diffing with Python
This tutorial will explore a simple approach to comparing objects from Speckle commits. Speckle is a data management platform that allows users to store, share, and manage data across multiple applications. The goal of this tutorial is to provide you with an understanding of and be able to build from the following:
-
Using Speckle SDKs
 : We will start by demonstrating how to use the SpeckleP SDK to retrieve and handle source data from Speckle. This will help you understand how to work with the Speckle platform more effectively and perform the comparison using the SDKs. (Jupyter Notebook)
: We will start by demonstrating how to use the SpeckleP SDK to retrieve and handle source data from Speckle. This will help you understand how to work with the Speckle platform more effectively and perform the comparison using the SDKs. (Jupyter Notebook) -
Basic Example in Python
 : Next, we will provide a simple Python implementation to compare JSON objects from two Speckle commits. This will help you understand the basic structure of the problem and how to approach it. (Jupyter Notebook)
: Next, we will provide a simple Python implementation to compare JSON objects from two Speckle commits. This will help you understand the basic structure of the problem and how to approach it. (Jupyter Notebook)
By the end of this tutorial, you should clearly understand how to compare objects from Speckle commits and how to choose the best approach based on your specific use case. ![]()
This is broken out of a mammoth notebook, so I’ve split it into bite-sized chunks. Subsequent parts of this Series will cover the following:
- Automation: Operating the comparison in response to new data,
- Processing at Scale: Best practices for making large comparisons,
- Identifying Similarity: Handling data without
applicationIds(did someone say ML?), - Data Auditing: Reporting on changed values and who changed them.
Using Speckle SDKs
The Speckle SDKs provide tools to help you work with the Speckle platform. In this tutorial, we will use the Speckle Python SDK (specklepy) to retrieve and handle source data from Speckle. The specklepy is a Python library that allows you to interact with the Speckle API and perform various operations on Speckle objects. You can find more information about the Speckle Python SDK here.
Installation
To install the Speckle Python SDK, you can use the following command:
pip install specklepy
In a Jupyter Notebook, I add some special sauce for cli tasks into the Jupyter kernel. This allows me to run the same code in a notebook as in a terminal. %%capture is a Jupyter magic command that captures the output of a cell, useful for installs which are noisy outputs
%%capture
%pip install specklepy
# dotenv is a library that allows you to load the environment
# variables from a .env file to avoid committing secrets to source control
%pip install python-dotenv
%reload_ext dotenv
%dotenv
Retrieving the Speckle commit data is a two-step process. First, we need to retrieve the commit object from the Speckle server. Then, we can use the commit object to retrieve the actual data. The following code snippet demonstrates how to retrieve the commit object from the Speckle server:
Authorisation
# boilerplate user credentials and server
import os
HOST_SERVER = os.getenv('HOST_SERVER')
ACCESS_TOKEN = os.getenv('ACCESS_TOKEN')
from specklepy.api.client import SpeckleClient
client = SpeckleClient(host=HOST_SERVER) # or whatever your host is
client.authenticate_with_token(ACCESS_TOKEN) # or whatever your token is
Getting Speckle Data
I will choose a stream and for this first simple example i will retrieve the latest commit to the main branch.
stream_id = "20e76a799c" # or whatever your stream id is
from specklepy.transports.server import ServerTransport
from specklepy.api.wrapper import StreamWrapper
transport = ServerTransport(client=client, stream_id=stream_id)
stream = client.stream.get(stream_id)
By default the commit.list() returns from most recent to oldest, so we can just take the first item in the list.
commits = client.commit.list(stream_id=stream_id, limit=2)
from specklepy.api import operations
# get obj id from latest commit
latest = commits[0].referencedObject
previous = commits[1].referencedObject
# receive objects from speckle
latest_data = operations.receive(obj_id=latest, remote_transport=transport)
previous_data = operations.receive(obj_id=previous, remote_transport=transport)
In this example I’m using a simple model from Rhino. This topmost object is a Collections object of type rhino model.
First Commit
Second Commit
The totalChildrenCount is 25, but those can be a nested structure of any depth. This is a collection of all the elements sent in that commit. This is a straightforward model for ease, but in principle, you will need to transform the nested data into a flat structure.
We have an example of how to do this in .NET in the Speckle Docs, but I’ll interpret it in Python here.
from collections.abc import Iterable, Mapping
from specklepy.objects import Base
def flatten(obj, visited=None):
# Avoiding pesky circular references
if visited is None:
visited = set()
if obj in visited:
return
visited.add(obj)
# Define a logic for what objects to include in the diff
should_include = any(
[
hasattr(obj, "displayValue"),
hasattr(obj, "speckle_type")
and obj.speckle_type == "Objects.Organization.Collection",
hasattr(obj, "displayStyle"),
]
)
if should_include:
yield obj
props = obj.__dict__
# traverse the object's nested properties -
# which may include yieldable objects
for prop in props:
value = getattr(obj, prop)
if value is None:
continue
if isinstance(value, Base):
yield from flatten(value, visited)
elif isinstance(value, Mapping):
for dict_value in value.values():
if isinstance(dict_value, Base):
yield from flatten(dict_value, visited)
elif isinstance(value, Iterable):
for list_value in value:
if isinstance(list_value, Base):
yield from flatten(list_value, visited)
NB: The Speckle ObjectLoader Javascript package also has a flatten function that can be used to do this. To do this with .NET and SpeckleSharp, the GraphTraversal methods can define a custom TraversalBreaker function.
You’ll also find flattening methods in some of our Connectors codes - choose your poison.
latest_objects = list(flatten(latest_data))
previous_objects = list(flatten(previous_data))
The task is to compare the two commits and find the differences.
from specklepy.objects.base import Base
from typing import List, Tuple
def compare_speckle_commits(
commit1_objects: List[Base], commit2_objects: List[Base]
) -> Tuple[List[Tuple[Base, Base]], List[Tuple[None, Base]], List[Tuple[Base, None]]]:
commit1_dict = {obj.id: obj for obj in commit1_objects[1:]}
commit2_dict = {obj.id: obj for obj in commit2_objects[1:]}
# Find unchanged objects
for obj_id in commit1_dict.keys():
if obj_id in commit2_dict.keys():
yield (commit1_dict[obj_id], commit2_dict[obj_id]) # old, new
# Find changed objects
for obj_id, obj in commit1_dict.items():
if obj_id not in commit2_dict.keys() and obj.applicationId in [
x.applicationId for x in commit2_dict.values()
]:
yield (
obj, # old object
[ x for x in commit2_dict.values()
if x.applicationId == obj.applicationId
][0], # new changed object
)
# Find added objects
for obj_id, obj in commit2_dict.items():
if obj_id not in commit1_dict.keys() and obj.applicationId not in [
x.applicationId for x in commit1_dict.values()
]:
yield (None, obj) # old, new
# Find removed objects
for obj_id, obj in commit1_dict.items():
if obj_id not in commit2_dict.keys() and obj.applicationId not in [
x.applicationId for x in commit2_dict.values()
]:
yield (obj, None) # old, new
NB: Thinking about processing
I am using lists in this first example, knowing that we are using a small data sample, but this is potentially an O(n^2) operation. Converting these to sets could improve this to O(n), but we will leave that for later. Perhaps I’ll award extra credit for community contributions. ![]()
Side note: Collections
Thinking ahead, I will store the results of this diff in Speckle itself. The Base commit object should reflect the desired result’s ‘shape’. We have recently added Collections to the Speckle Core. specklepy will soon sync with Speckle-sharp and include the Collections object, but for now, we can use an in-place version from this example.
from typing import Optional
class Collection(
Base, speckle_type="Objects.Organization.Collection", detachable={"elements"}
):
name: Optional[str] = None
collectionType: Optional[str] = None
elements: Optional[List[Base]] = None
The Diff
The meat and potatoes of the comparison are the diff function. This recursive function will compare the two objects and return a list of differences. It will sort the objects into four categories: added, removed, modified, and unchanged.
The ‘modified’ category is the most interesting. It will use the applicationId to determine if an added object is the same as a removed object. If it is, it will be marked as modified. If not, the objects from previous and latest will be marked as added and removed.
Highlighting what has changed is beyond the scope of this tutorial, but you can use the diff function to find the differences and then use just those ids to limit the scope of your more intensive comparison.
# Compare two Speckle commits and populate a base object with the results
def store_speckle_commit_diff(commit1_objects, commit2_objects):
diff = {
'changed': [],
'added': [],
'removed': [],
'unchanged': []
}
for obj in compare_speckle_commits(commit1_objects, commit2_objects):
if getattr(obj[0], "id", None) == getattr(obj[1], "id", None):
diff["unchanged"].append(obj[0]) # old object, though it's the same as the new object
elif (
obj[0] is not None
and obj[1] is not None
and getattr(obj[0], "id", None) != getattr(obj[1], "id", None)
):
diff["changed"].append(obj[1]) # new object
elif obj[0] is None and obj[1] is not None:
diff["added"].append(obj[1]) # new object
elif obj[0] is not None and obj[1] is None:
diff["removed"].append(obj[0]) # old object
return diff
NB: Processing at scale.
A subsequent part of this tutorial will revisit this methodology which requires a lot of data held in memory as source and result. Various options might spring to mind for handling when that gets large, but that is for another day.
The Results
Let’s use Speckle to store the results.
diff_result = Base(name="Diff")
unchanged = Collection(
name="Unchanged",
elements=[
o
for o in diff["unchanged"]
if o.speckle_type != "Objects.Organization.Collection"
],
collectionType="Unchanged Objects",
)
changed = Collection(
name="Changed",
elements=[
o
for o in diff["changed_to"]
if o.speckle_type != "Objects.Organization.Collection"
],
collectionType="Changed Objects",
)
added = Collection(
name="Added",
elements=[
o for o in diff["added"] if o.speckle_type != "Objects.Organization.Collection"
],
collectionType="Added Objects",
)
removed = Collection(
name="Removed",
elements=[
o
for o in diff["removed"]
if o.speckle_type != "Objects.Organization.Collection"
],
collectionType="Removed Objects",
)
diff_result["@unchanged"] = unchanged
diff_result["@changed"] = changed
diff_result["@added"] = added
diff_result["@removed"] = removed
obj_id = operations.send(base=diff_result, transports=[transport])
commit_id = client.commit.create(
stream_id=transport.stream_id,
object_id=obj_id,
message="Diff!",
branch_name="diffs",
)
With those three objects, we can now compare what has changed.
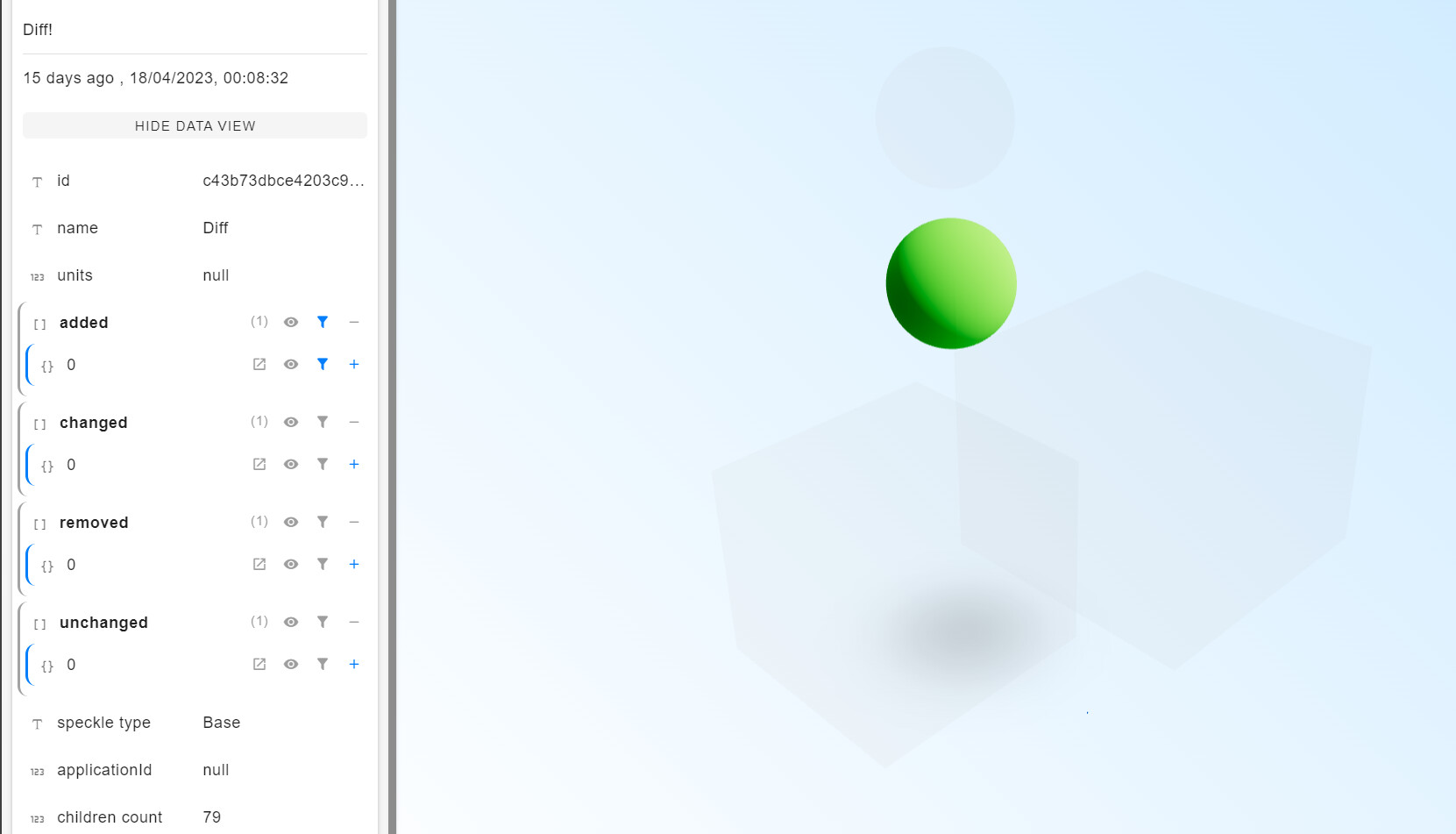

With just the added and removed objects, we can start to show which are the same objects represented by a different hash.
Wrapping up
This basic example will examine the applicationIds property* of the Speckle objects and compare the values of the two commits. If the values are found in both added and removed, the object will be added to the changed list. If the values are found in the added list only, then the object will be added to the added list. If the values are found in the removed list only, then the object will be added to the removed list.
Just a few additional notes:
-
Keeping this diff commit separate is a very good idea because the diff is a programmatically committed version of the source data.
-
But given that it is an analysis result, we could amend the
displayValuesof those objects to reinforce what the data structure shows. The classic red-amber-green is typical. -
Not all software produces reliable
applicationIds, so this method is not foolproof. It is a good starting point, but you may need to use other properties to determine if two objects are identical. -
This simplified version of the diff process might not work for every scenario. For example, if the model has been manipulated in such a way that the
applicationIdof an object changes (e.g., an object was deleted and a new one was created in its place), this will be detected as a removed and added object, not a modified one. -
The diff operation can be quite resource intensive depending on the size of the commits. It’s generally a good idea to limit the scope of the diff to the parts of the model you’re interested in, if possible.
-
Lastly, it’s important to mention that the diff operation is performed locally on your machine using the data fetched from the server. Your machine needs sufficient resources to perform this operation, especially for large models.
Next Time: Automation
The next tutorial will cover automating the comparison process using the Speckle SDKs. This will demonstrate running analysis in response to change as indicated by new commits to a stream.