In Part 1 ![]() , I introduced programmatic Version diffing of Speckle data
, I introduced programmatic Version diffing of Speckle data ![]() . In this part, I will show how this simple example can be deployed to respond to new commits on a branch. This uses the Speckle webhook functionality
. In this part, I will show how this simple example can be deployed to respond to new commits on a branch. This uses the Speckle webhook functionality ![]() .
.
In the example of Rhino models being incrementally amended and Versions committed to Speckle, the comparison is between the latest and the immediately previous Version. In a webhook scenario, the comparison is between the latest and current versions when the webhook was triggered. This is because the webhook is created against a specific commit, and the webhook is triggered when a new commit is made ![]() .
.
NB: With automation, we could trigger the program with each new commit, making our system more efficient. Of course, if you’re making more commits than a barista makes lattes during the morning rush, you might end up with duplicate results. No one needs two lattes at once… unless it’s a Monday. ![]()
![]()
Recapping the basic functionality  :
:
# boilerplate user credentials and server
import os
HOST_SERVER = os.getenv('HOST_SERVER')
ACCESS_TOKEN = os.getenv('ACCESS_TOKEN')
from specklepy.api.client import SpeckleClient
client = SpeckleClient(host=HOST_SERVER) # or whatever your host is
client.authenticate_with_token(ACCESS_TOKEN) # or whatever your token is
stream_id = "20e76a799c" # or whatever your stream id is
from specklepy.transports.server import ServerTransport
from specklepy.api.wrapper import StreamWrapper
transport = ServerTransport(client=client, stream_id=stream_id)
stream = client.stream.get(stream_id)
commits = client.commit.list(stream_id=stream_id, limit=2)
from specklepy.api import operations
# get obj id from latest commit
latest = commits[0].referencedObject
previous = commits[1].referencedObject
# receive objects from speckle
latest_data = operations.receive(obj_id=latest, remote_transport=transport)
previous_data = operations.receive(obj_id=previous, remote_transport=transport)
But wait!![]() The
The commit.list is getting us the last two commits. But in Part 1 of this tutorial we made a “Diff!” commit.
Sensibly, however, the part 1 Diff commit was made on a separate Model branch. This is one of the advantages of using branches in general, partitioning versions for later recall.
To query a specific branch for commits, we use a different part of the Client API ![]() :
:
# Add the branch name as a query filter,
# limit changes to commits_limit for this call.
main_branch_commits = client.branch.get(
stream_id=stream_id, name="main", commits_limit=2
)
main_branch_commits.commits.items
There are our two original commits.


[
Commit(
id: 1ebb510278,
message: Second Commit,
referencedObject: e44034f90b817573270cc3ec2534c74f,
....
),
Commit(
id: 2bf8b491ce,
message: First Commit,
referencedObject: 9e18b762dd52788a457de6a7b961d428,
....
)
]
NB: Notice the order they are received, newest first. A bit like your social media feed, but with less cat videos and more productive outcomes!
But we need to go further – If responding to a commit event, we must request that specific commit and the immediately preceding one.
We can inspect the properties of the webhook to determine how to do that.
Webhooks 
Webhooks can be thought of as our program’s very own personal assistant. They’ll let us know when something we care about, like a new commit, happens. Just be warned, they won’t fetch you coffee or laugh at your jokes. Believe me, I’ve tried. ![]()
We write about Speckle Webhooks in the docs, so I won’t go into great detail here except to show what would be the setup in this case ![]() .
.
The webhook setup: url, description(optional), secret(optional) and events
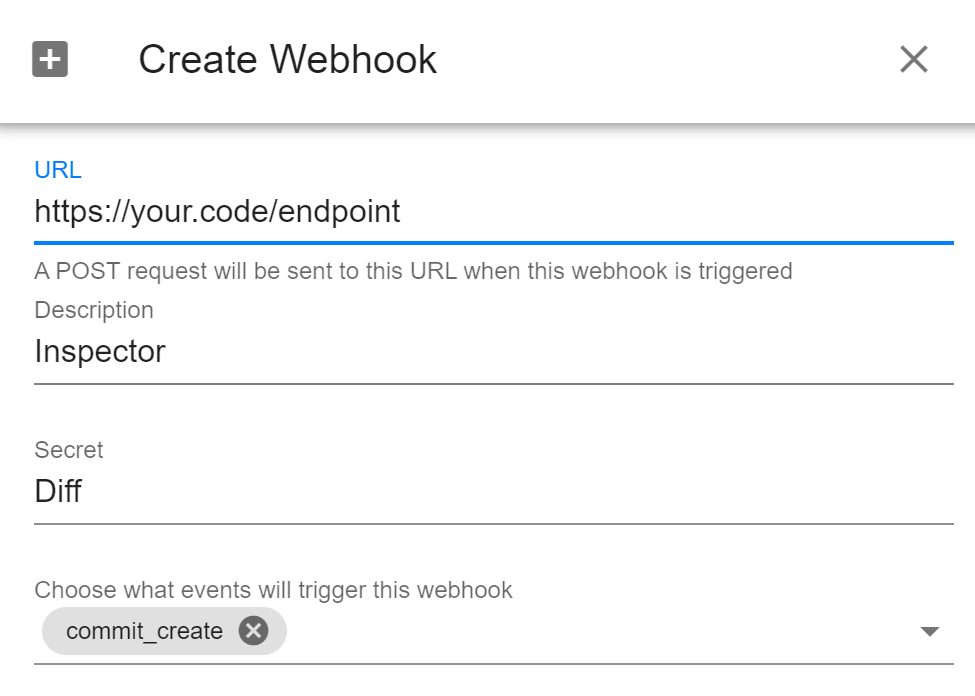
and the resultant payload from a new commit is added:
{
"payload": {
...
"event": {
"event_name": "commit_create",
"data": {
"id": "1ebb510278",
"commit": {
"message": "Second Commit",
"objectId": "e44034f90b817573270cc3ec2534c74f",
"sourceApplication": "Rhino7",
"branchName": "main",
"authorName": "Jonathon",
}
}
},
"server": {
...
},
"stream": {
"id": "20e76a799c",
"name": "Diffing Demo",
"createdAt": "2023-04-16T17:17:05.058Z",
...
},
"user": {
...
"name": "Jonathon",
...
},
"webhook": {
"id": "a77eb6c427",
"streamId": "20e76a799c",
"url": "https://your.code/endpoint",
"triggers": [
"commit_create"
]
}
}
}
Critical parts of this worth noting are the event_name and the data object. The event_name is the event that triggered the webhook. In this case, it is commit_create. The data object contains the commit object, which contains the id of the created commit.
The flatten function we can reuse from before.
# Flatten the objects into a list of objects
def flatten(obj, visited=None):
....
And the comparison function ![]() :
:
# Compare two Speckle commits and populate a List of tuples
def compare_speckle_commits(
....
To vary the example to a different use case, I have amended the store_speckle_commit_diff function only to report changed elements grouped by their applicationId. This could be useful if you are updating a separate database. In this case, the two things worth noting would be DELETE representing an element that was removed, UPDATE representing an element that was changed and INSERT representing an added element.
def report_speckle_commit_diff(commit1_objects, commit2_objects):
diff_report = []
for obj in compare_speckle_commits(commit1_objects, commit2_objects):
object_report = {"applicationId": obj[1].applicationId,
"data": obj[1].to_dict()}
if getattr(obj[0], "id", None) == getattr(obj[1], "id", None):
continue # Skip unchanged elements
if obj[0] is not None and obj[1] is not None:
object_report["verb"] = "UPDATE"
elif obj[0] is None and obj[1] is not None:
object_report["verb"] = "INSERT"
elif obj[0] is not None and obj[1] is None:
object_report["verb"] = "DELETE"
diff_report.append(object_report)
return diff_report
That diff_report would likely suffice for any follow-on script you might want to take using those database instructions. But for storing this report in Speckle itself for posterity, we can convert it into a Speckle object and commit it to the stream.
# convert the diff report to a speckle base object
from specklepy.objects import Base
from specklepy.objects.other import Collection
def diff_report_to_speckle_base(diff_report):
commit = Collection(collectionType="diff_report",
name="diff report",
elements=[])
deleted = Collection(collectionType="deleted objects",
name="deleted objects",
elements=[])
updated = Collection(collectionType="updated objects",
name="updated objects",
elements=[])
inserted = Collection(collectionType="inserted objects",
name="inserted objects",
elements=[])
for obj in diff_report:
target_collection = None
if obj["verb"] == "DELETE":
target_collection = deleted
elif obj["verb"] == "UPDATE":
target_collection = updated
elif obj["verb"] == "INSERT":
target_collection = inserted
target_collection.elements.append(Base.from_dict(obj["data"]))
commit.elements.extend([deleted, updated, inserted])
return commit
For this example, I’ll deploy this webhook handler as a Google Cloud Function (other methods exist), so we’ll import the functions_framwork package. And load in the secrets from environment variables.
#GCP SDK for cloud functions
import functions_framework
import os
HOST_SERVER = os.getenv('HOST_SERVER')
ACCESS_TOKEN = os.getenv('ACCESS_TOKEN')
GCP_API_USER = os.getenv('GCP_API_USER')
GCP_API_KEY = os.getenv('GCP_API_KEY')
GCP_PROJEC = os.getenv('GCP_PROJECT')
@functions_framework.http is the function decorator that will allow us to deploy this as a Google Cloud Function triggered by an HTTP request.
My webhook handler looks like this:
from specklepy.api import operations
@functions_framework.http
def diffing_handler(request):
# Retrieve payload from the request
payload = request.get_json()
# Check if the event is a commit creation event
event = payload.get('event')
if not event or event.get('event_name') != 'commit_create':
return 'Not a commit created event', 204
NB: It’s a good idea to check that the event that triggered the webhook is what we expect. We wouldn’t want a surprise party for commit_create when we were expecting commit_delete , would we?
# Retrieve branch name from the payload
branch_name = payload['data']['commit'].get('branch_name')
if not branch_name or branch_name != 'main':
return 'Commit not on the main branch', 400
....
NB: To be defensive, we should check that the event that triggered the webhook is what we expect. In this case, we are expecting commit_create. In addition, we want to limit the webhook to only responding to commits on the main branch. This is because we are only interested in commits made to the main branch. We can do this by checking the branchName property of the commit object. The handler could be protected further by using the webhook secret to sign the payload and verify the signature. This is not covered here. But this is a good idea if you are deploying a webhook handler to a public endpoint. But in particular, it can distinguish between different workloads triggered by the same webhook event to different endpoints.
....
# Retrieve stream ID and commit ID from the payload
stream_id = payload['stream']['id']
commit_id = payload['data']['id']
# Get a list of recent commits from the main branch
commits = client.branch.get(branch_name, stream_id=stream_id,
commits_limit=10).commits.items
# Find the consecutive commits that match the commit ID
consecutive_commits = [
commits[i:i+2]
for i in range(len(commits)-1)
if commits[i].id == commit_id
]
if consecutive_commits:
latest, previous = consecutive_commits[0]
else:
return 'Commit not found', 404
# Get the referenced objects from the consecutive commits
latest = commits[0].referencedObject
previous = commits[1].referencedObject
# Receive the object data from Speckle
latest_data = operations.receive(obj_id=latest,
remote_transport=transport)
previous_data = operations.receive(obj_id=previous,
remote_transport=transport)
# Flatten the object data lists
latest_objects = list(flatten(latest_data))
previous_objects = list(flatten(previous_data))
# Generate the diff report between the previous and latest objects
diff_report = report_speckle_commit_diff(
previous_objects,
latest_objects
)
# Convert the diff report to a Speckle base object
diff_commit = diff_report_to_speckle_base(diff_report)
# Send the diff report object to the Speckle server
obj_id = operations.send(base=diff_commit, transports=[transport])
# Create a new commit with the diff report
client.authenticate_with_token(ACCESS_TOKEN) # or whatever your token is
diff_commit_id = client.commit.create(
stream_id=stream_id,
branch_name="diffs",
message=f"diff report for commit {commit_id}",
source_application="diffing",
object_id=obj_id,
)
# Return success response with the diff commit ID
return f"diff report created with id {diff_commit_id}", 200
NB: In an ideal world, we’d separate the webhook handler from the deployment code, but let’s be honest, this isn’t a cooking show where everything is pre-prepared, and we pull the finished dish out of the oven. We’re keeping things real and simple for this tutorial. Separating the two would allow us to deploy the webhook handler to other platforms and allow for testing of the webhook handler without having to deploy it ![]() .
.
I won’t go into detail about deploying a Google Cloud Function, but the code is available in the GCP docs. The important thing to note is that the function is deployed to a specific endpoint. In this case, it is https://{{CLOUD_REGION_GCP_PROJECT}}.cloudfunctions.net/diffing_handler. This is the endpoint that we will use when creating the webhook.
Summing Up
And there we have it – a look under the hood of automating version diffing with Python. In the span of this tutorial, we’ve set up triggers, tamed webhooks, and sidestepped surprise parties – all in the name of efficient computing. The moral of the story? With a little Python magic, we can coax our machines into being even more helpful without necessarily resorting to bribery with coffee or robotic laughter.
But this is just the tip of the proverbial iceberg. As with any journey, there’s always room for improvement and evolution. Your feedback, questions, and even your wild brainstorming ideas are the fuel that drives this community. So don’t hold back – share your thoughts, experiences, and even your ‘aha’ moments as you’ve followed along with this tutorial. Remember, it’s in our collective tinkering and mutual curiosity that the best innovations are born.
If you thought this was fun, you’re in for a treat. Hold onto your hats for Part 3, where we’ll kick things up a notch and delve into the world of multithreading and other power-processing methods. This next adventure promises to take your Python prowess to new heights, or at the very least, it’ll keep your CPU cores busy. So, stay tuned and keep those coding fingers limber. ![]()
Until next time, happy coding!