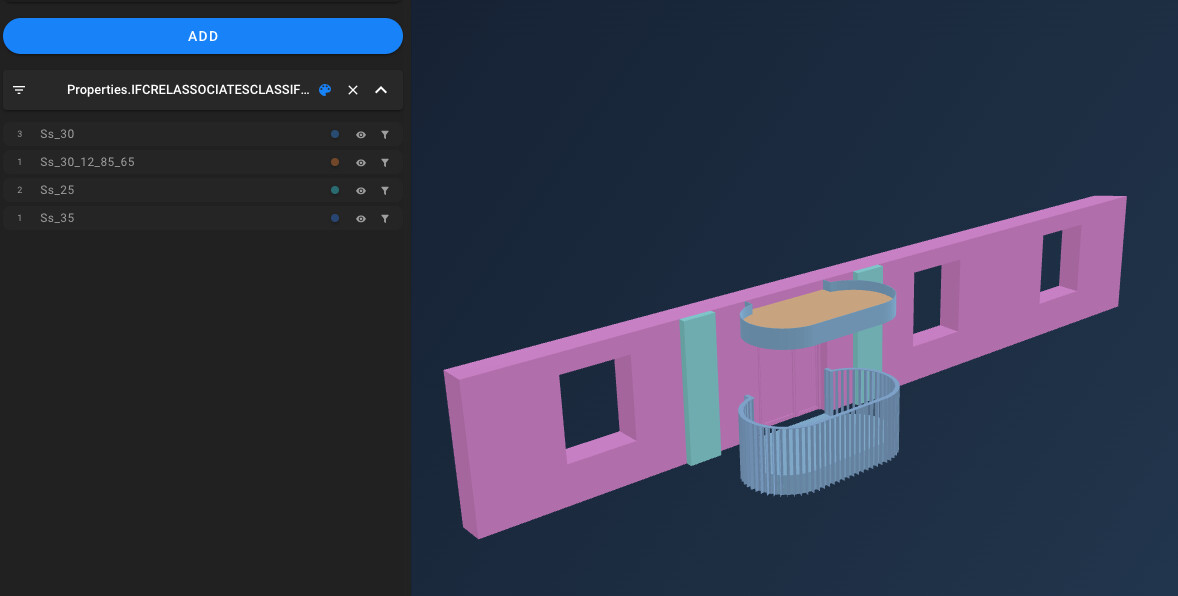
I’m hoping the great and the good of the Speckleverse can help out my full brain  and I am seeking any thoughts around the various options for the Objects.Navis object model.
and I am seeking any thoughts around the various options for the Objects.Navis object model.
Background
All Navisworks models are an aggregation of n models which are represented as a hierarchical tree 
File > Level > Element > Component > Geometry being the flattest, most basic example.
Each of these nodes is a List of that type. Different sources will populate the Model data attached to any of these nodes and it will vary by file type (e.g. Revit) and which node it applies it to. In order to aggregate many formats of the source models, the hierarchy will be different by type, reflecting how best to maintain informational and geometrical data completeness in a logical inheritance. If you imagine Type/Instance data being present on parents and children of a nested family, this may make sense to you. What may not is that depending on element type this may be arbitrarily applied at the Category, Type OR geometry level.
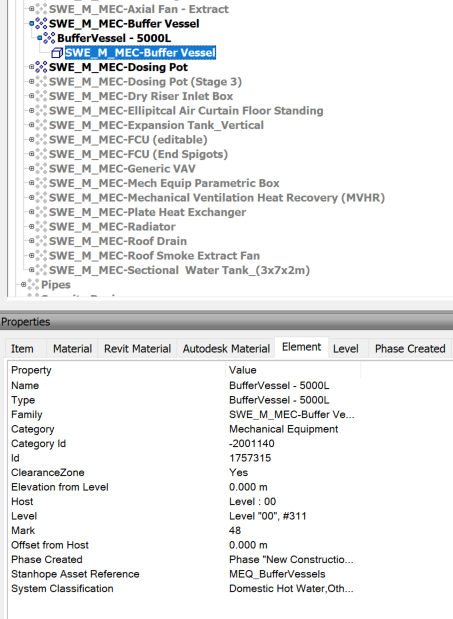
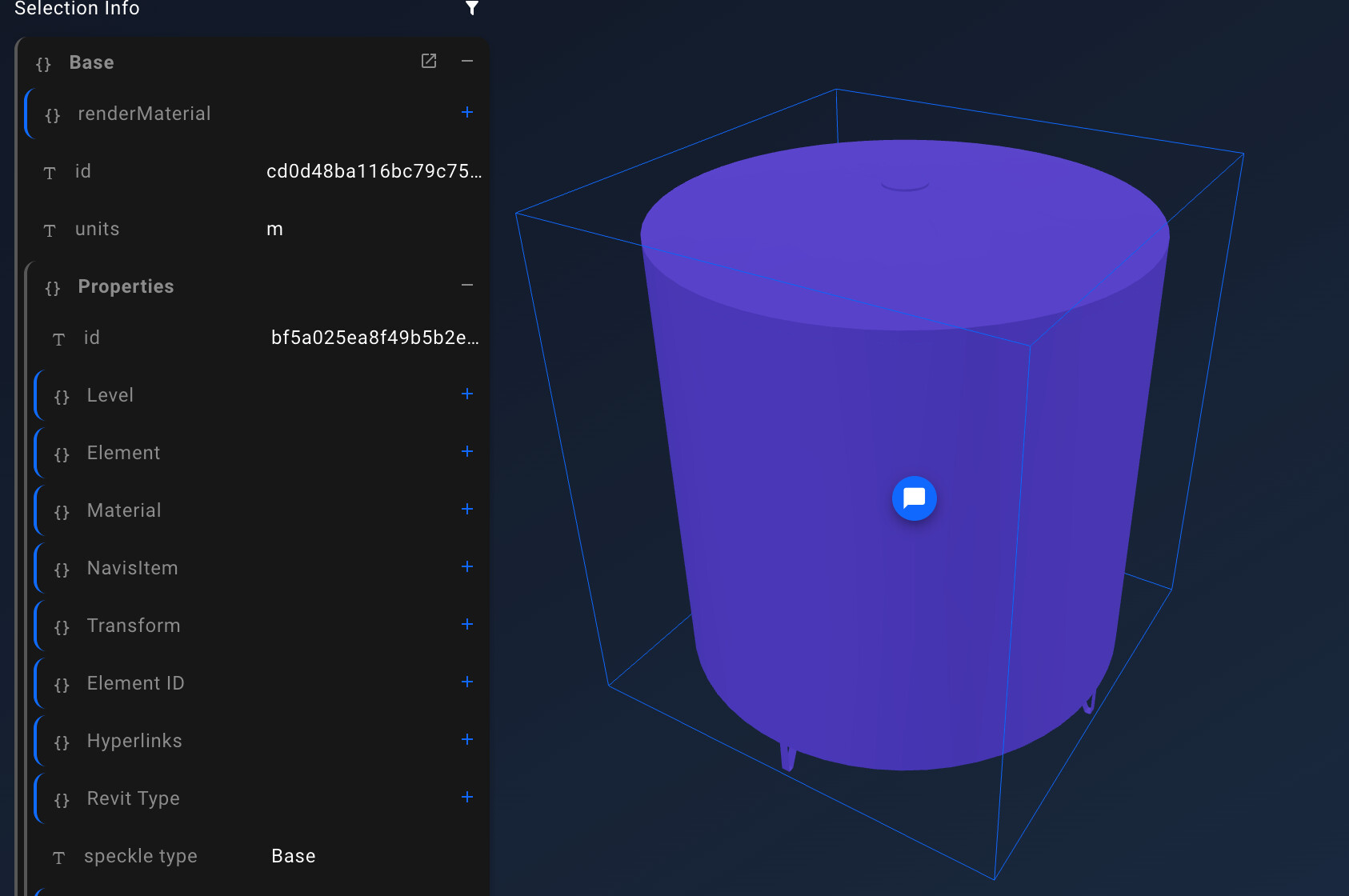
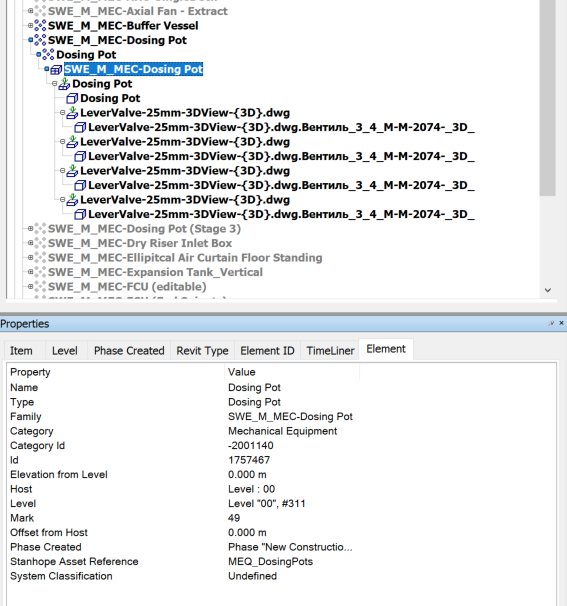
A closer look at a real-world example shows that the geometry of the model may be at inconsistent depths depending on the source. the  s indicate a geometry node.
s indicate a geometry node.
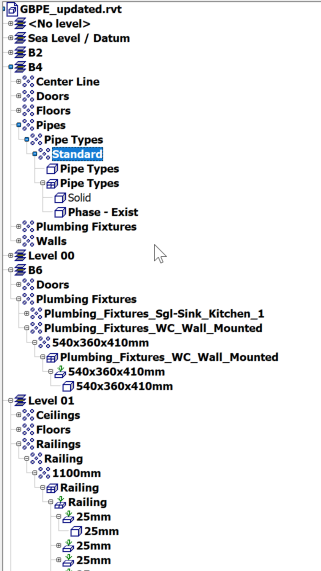
When the source is aggregated models from different authors, file sources and formats the resultant tree is, while logically consistent, difficult to manage as a data structure.
Solutions
I have sketched out 4 possible Speckle object structures to represent the information in a given selection of these model elements in a commit. Each has Pros and Cons which I’m still thinking about. The first is what the Rimshot App finished the hackathon with. Stream attached.
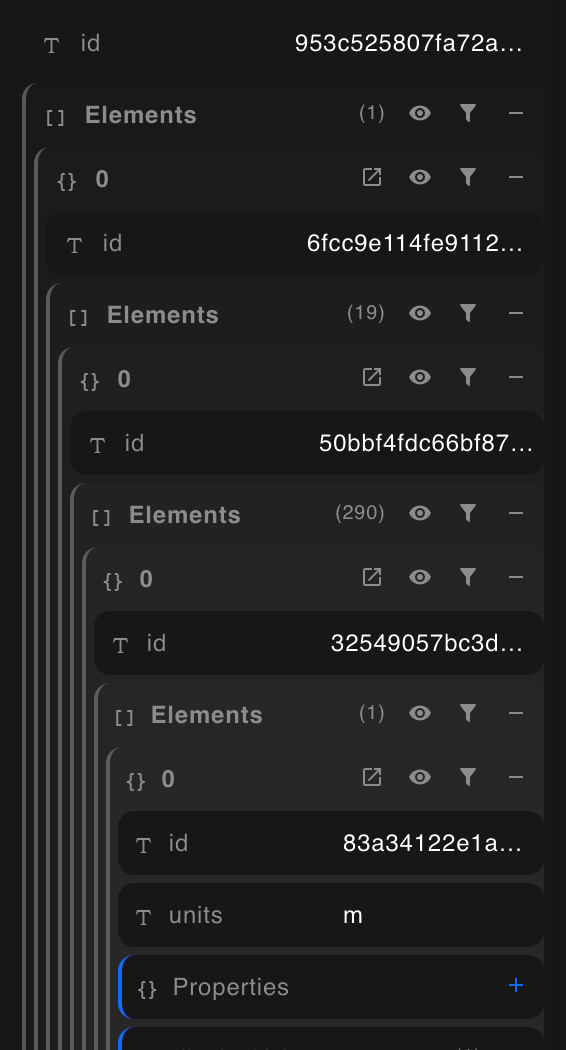
The Tree-Object model (as currently implemented)
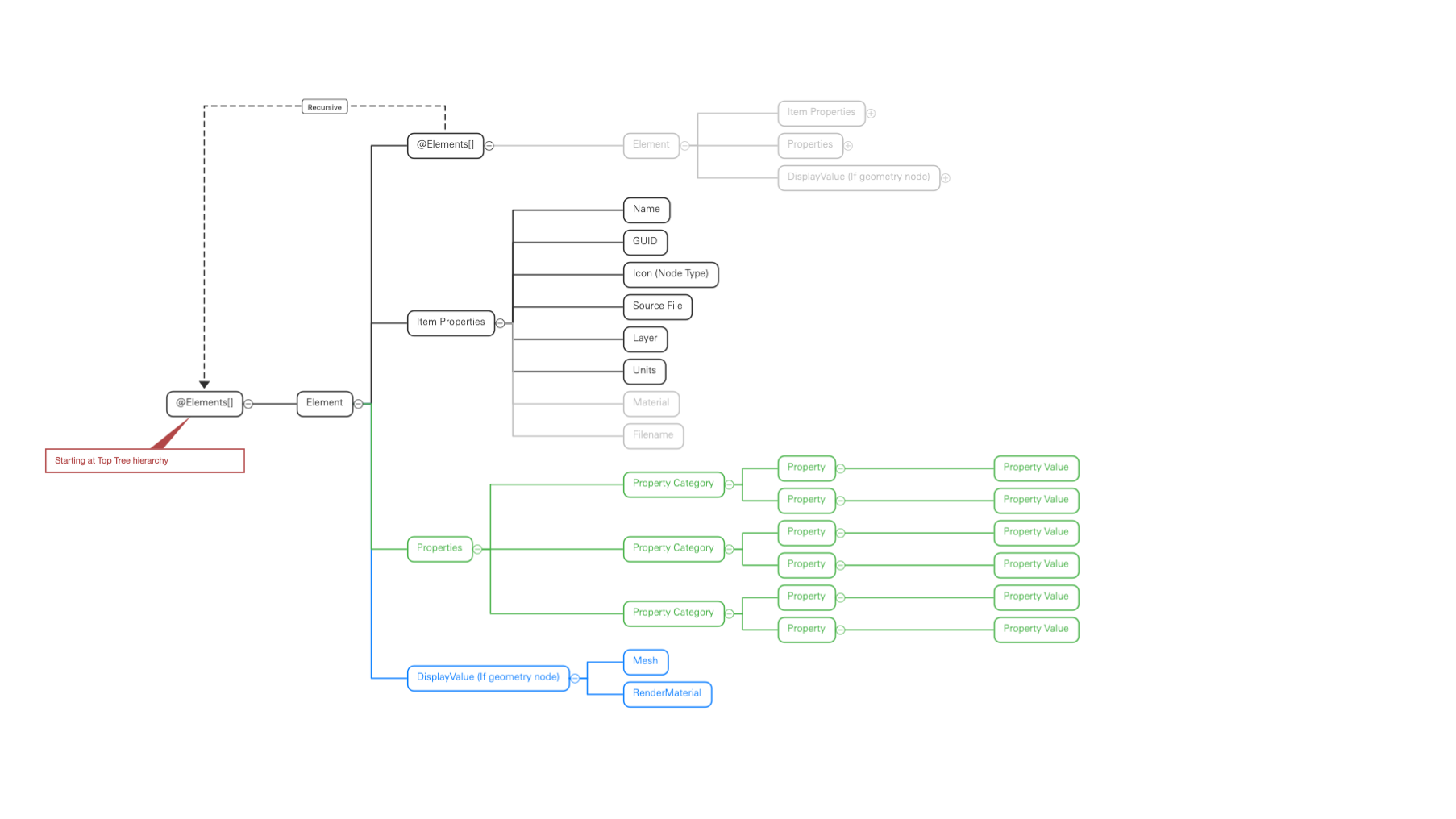
This is the implementation using Base objects of this nested tree. Each node is a Base object (Element) that in turn contains @Elements[] with each node being otherwise generically the same until the final ‘leaf’ node which is ALWAYS a geometry node.
Pros:
- Maintains the parity with the source information
- No duplicate Elements
- Filtering by properties cascades to include/exclude descendant nodes
Cons:
- The nesting of Elements is unknowable and requires recursion
- The geometry nodes are potentially at many arbitrary depths (e.g. v. difficult to handle generically in grasshopper)
attempting to map parent element property lists with child element geometry nodes from a quite simple demo file
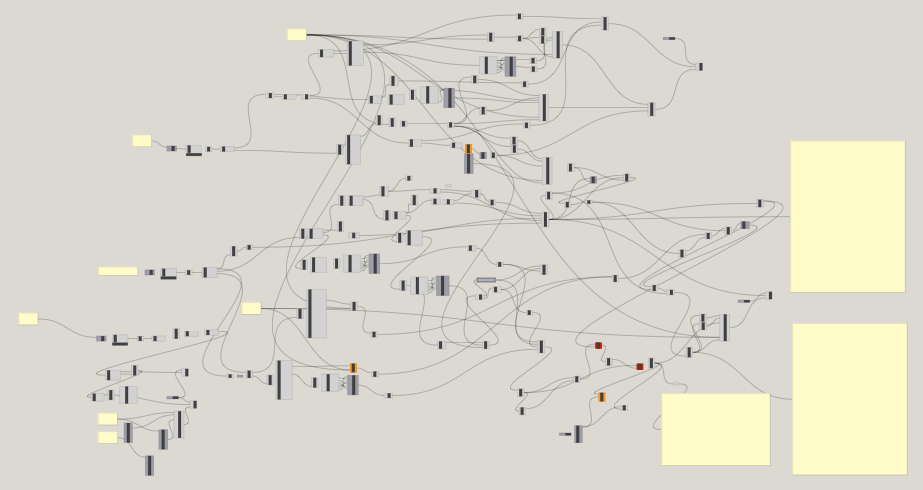
- When it is deep nesting from IFC, say, it gets hairy.
The Reverse-Tree-Object model
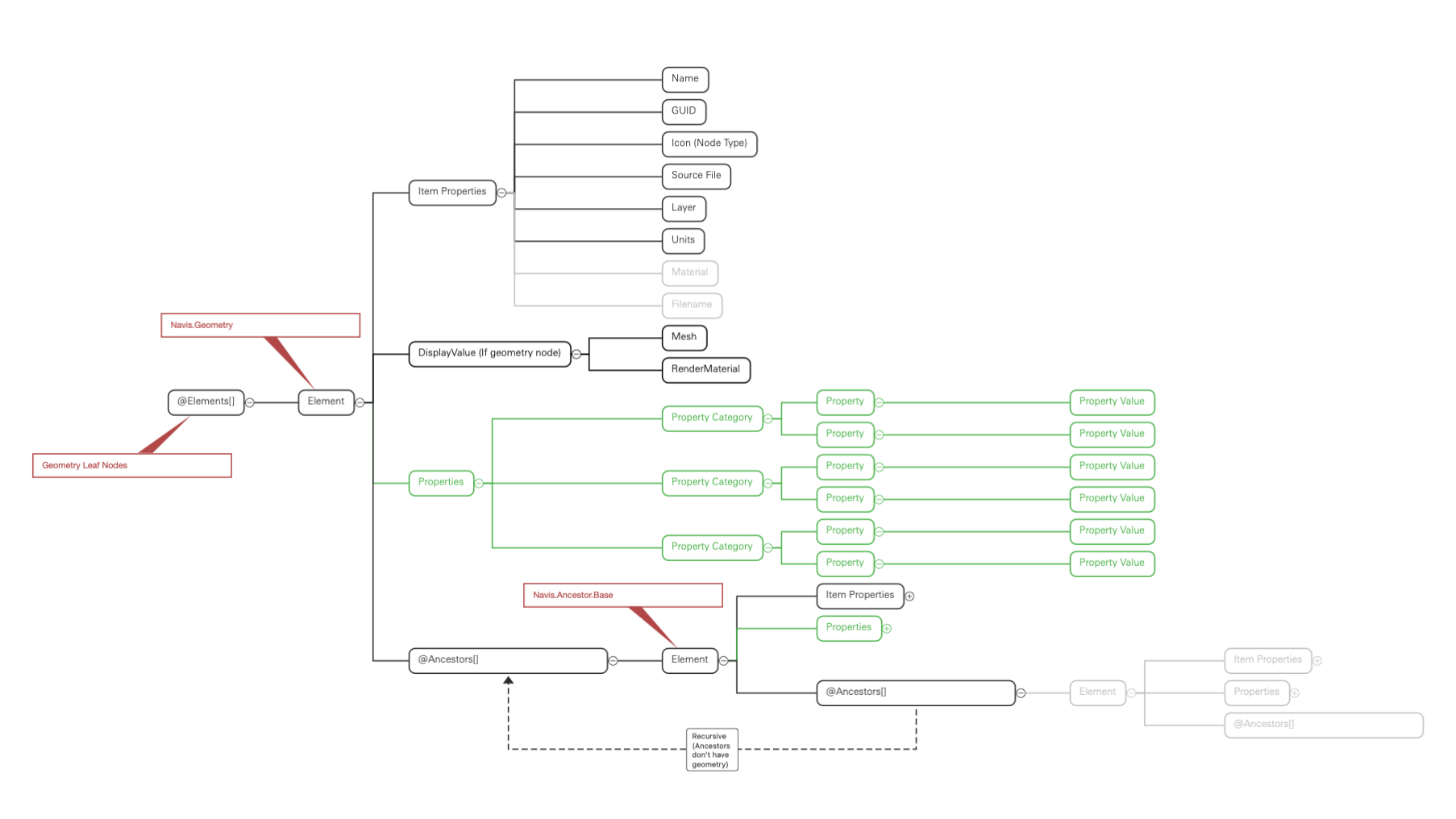
This starts with all Geometry nodes at the root and recursively records Ancestor nodes as a tree of geometryless Element objects
Pros:
- Position of geometry is consistent and knowable
- Ancestor data is retrievable is required
Cons
- Accessing ancestor data properties requires recursion
- Potential for duplicate Ancestors (obviated by detaching)
Ancestry-Element-List model
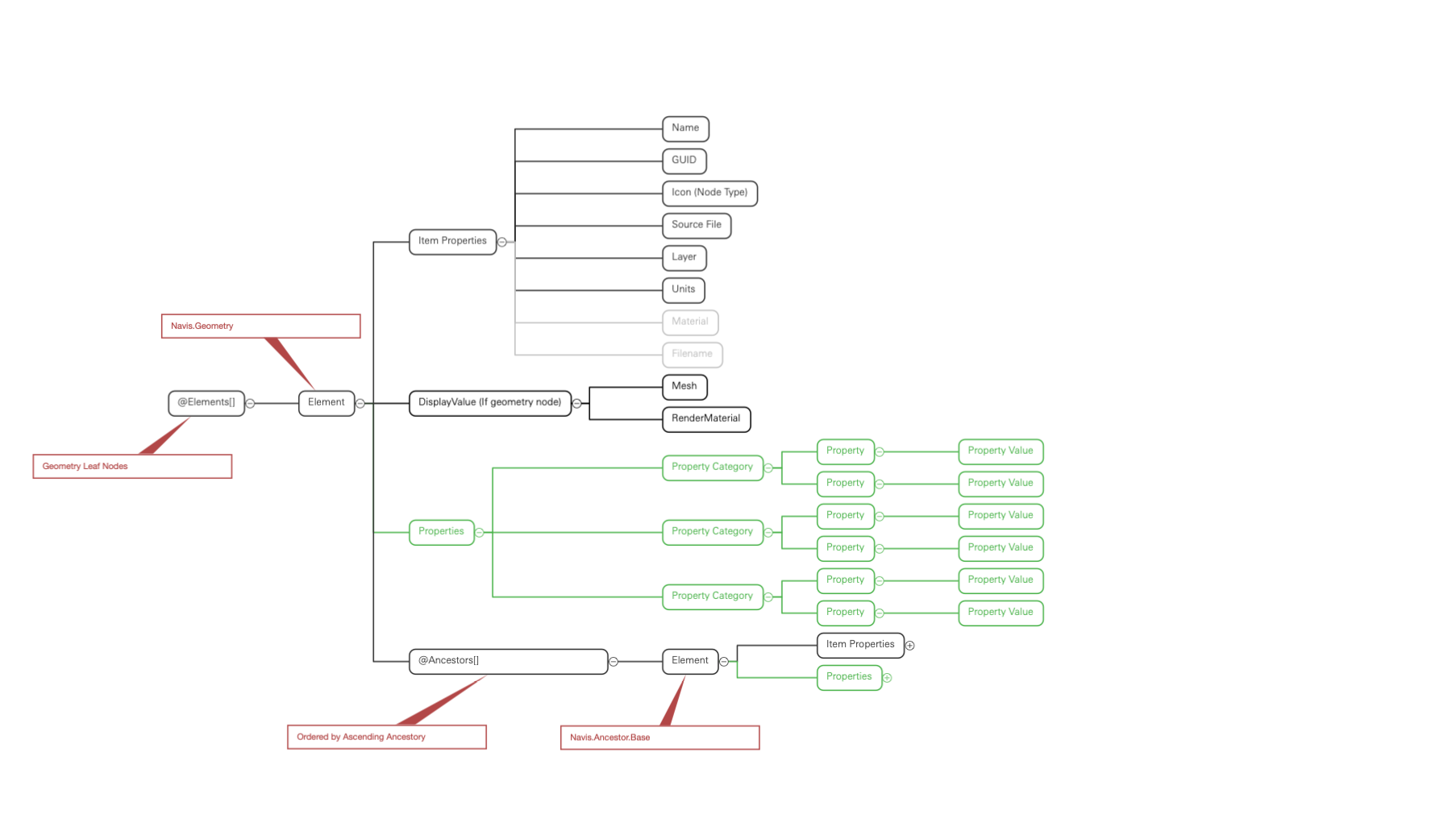
This replaces the object tree of ancestors with a List ordered by the depth of the ancestor node in the tree.
Pros:
- Position of geometry is consistent and knowable
Cons: - Potential for duplicate Ancestors elements (obviated by detaching)
- The parity of each ancestor list item and its source node will be lost as compared between geometry objects.
- Accessing ancestor data properties requires looping
Ancestry-Property-List model
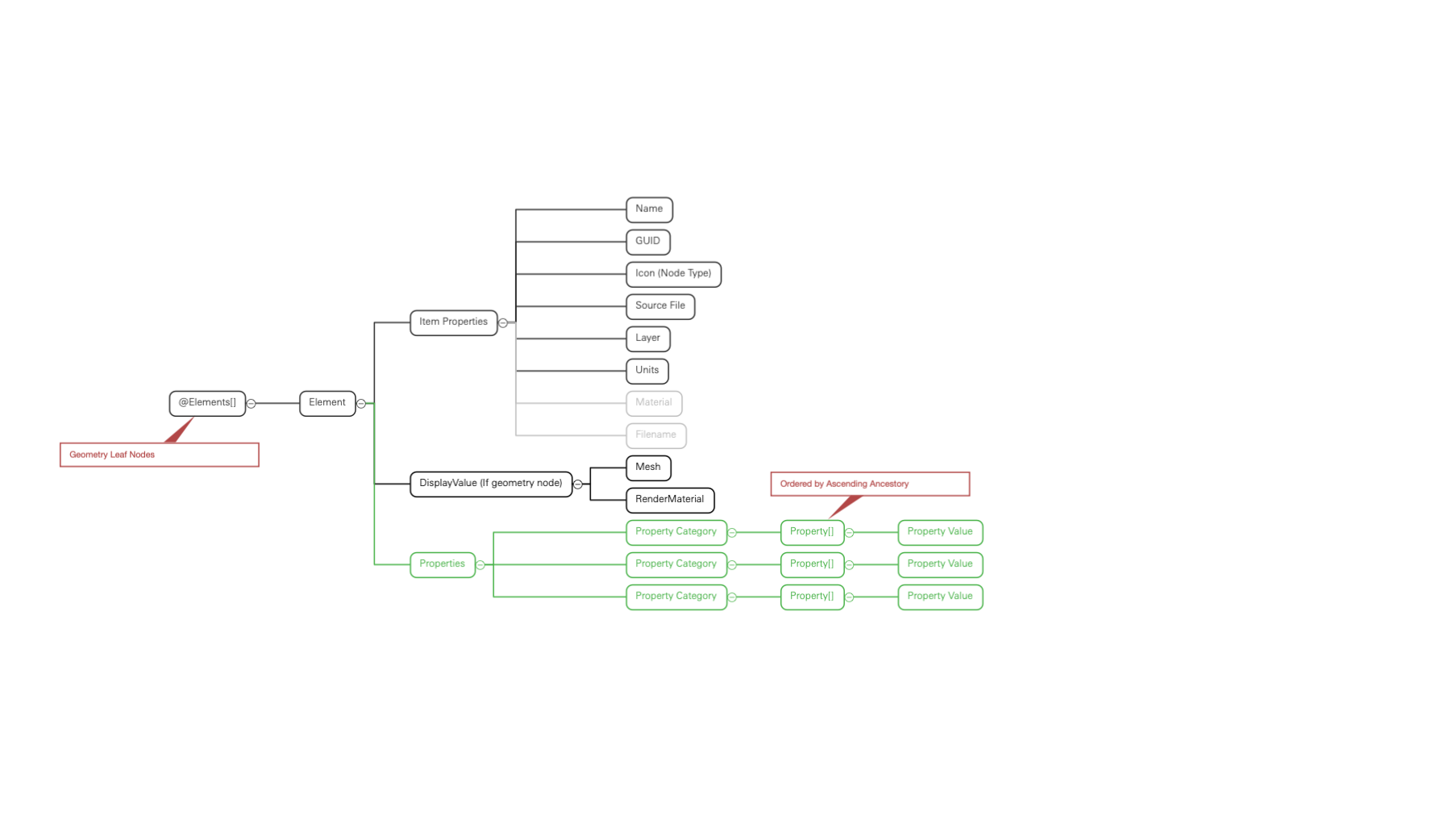
Instead of ancestor nodes in a list, the properties of the geometry are populated as lists for each category:property_name ordered by the depth of the ancestor node in the tree
Pros
- All data preserved for a Geometry leaf node.
- Filtering by properties is straightforward (maybe not by the viewer)
- No duplicate objects (property values may be duplicated but I’m assuming detaching is unnecessary)
Cons:
- As ancestors may or may not have particular properties, the parity of each list item and its source node will be lost
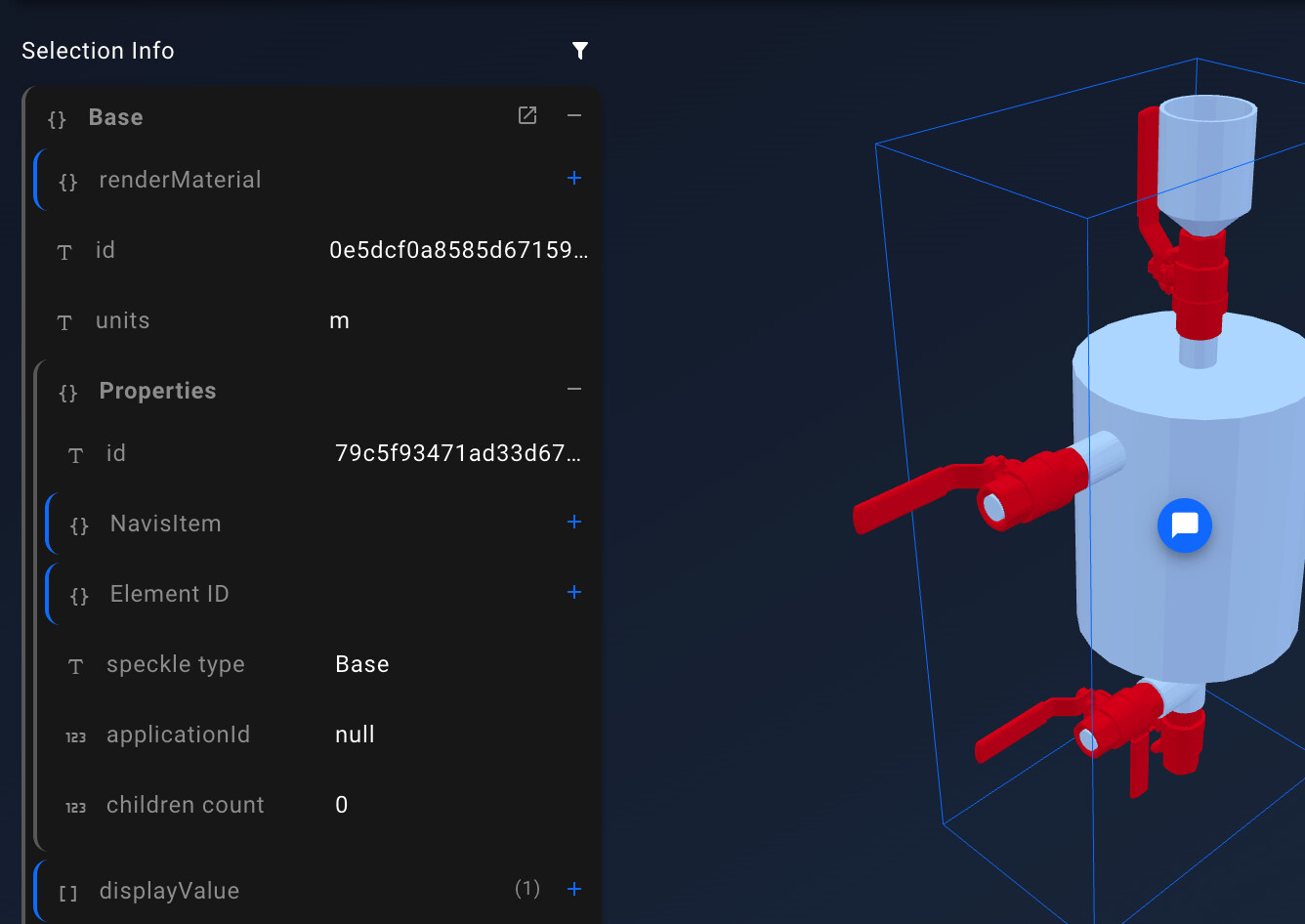
 valves are:
valves are: