Hi, I may finally have a reason to work with Speckle and am stoked and also upset I didn’t make the connection (pun) sooner. I’ve done a first read through the developer docs and want to sanity check my understanding of what’s possible with you all:
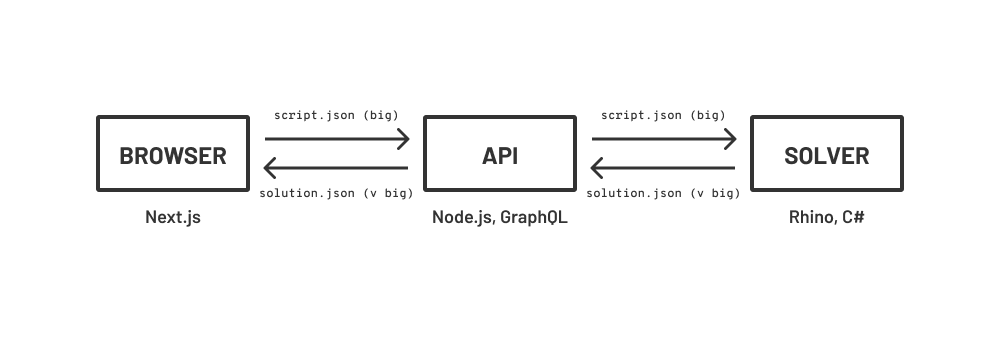
I have a web client that composes .json representations of Grasshopper graphs. It sends them to a node.js api, and the api schedules them for parsing/execution on a Rhino Compute server. These json files are already large, and the results from Rhino quickly get larger. The client has trouble loading (or even receiving) these giant json files and adding them to a three.js scene. Salt in the wound is that there’s often very few actual differences from what it already has loaded.
I realized “streaming geometry to a 3D model, specifically Rhino geometry” is something Speckle does incredibly well and took a look at the Grasshopper connectors. Forgive the sloppy understanding, but it looked like something like this could be possible:
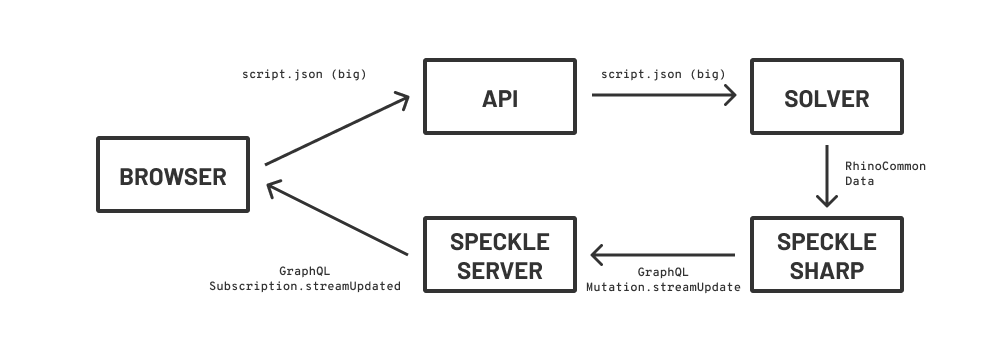
At a glance, it looks like I can push rhino geometry to a model stream from the C# solver service and subscribe to those changes from the client. This is great because of all the Speckle perks that come with it, but also because it solves my “model v big” problem.
My setup is a little different than what it felt like the docs were for (I don’t have an open Grasshopper script, for example) so I kept reading. And this is where things started to sound too good to be true and why I’m writing this post.
I have a few specific constraints and conditions in my setup:
- The script.json object uses an (annoyingly) bespoke object structure
- The .gh created from this .json must preserve ids for the components (overwrite defaults from Grasshopper)
- The result from Grasshopper can’t just be a pile of geometry, I have to preserve:
- Which geometry belongs to which component and parameter
- Where in the Grasshopper data tree structure the geometry lives
- Extra computed information beyond the RhinoCommon data, like bounding boxes, associated and stored as json
- There is no persistently-running grasshopper script, compute is scaled up/down as needed
- The client model needs to do more than view the results, and needs to be able to associate element ids with their geometry
- The model must reflect selection status on the client (i.e. highly geometry if component is selected)
- The model must respond immediately to visibility changes if a component is hidden
So it felt like I couldn’t use the out-of-the-box connectors. And then I read that connectors, kits, and transports can be created at-will and interact with speckle just fine. If I understand this correctly, Speckle doesn’t care if the json I’m sending around is a grasshopper script or Rhino geometry, and I may be able to create my replace my entire stack with a Speckle-based one:
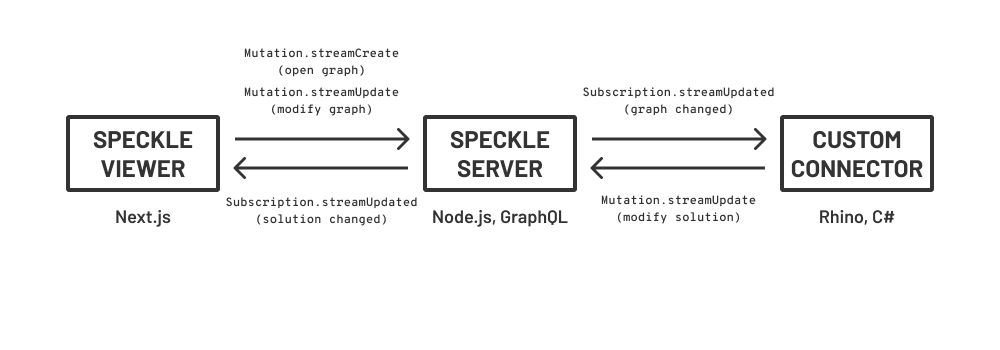
The order of events would be something like:
- User visits site, opens a script, creates a new stream based on script.json data that exists somewhere
- User changes script and client pushes custom object changes to speckle server
- C# compute service (or some JS gateway service), via subscription, is able to identify that graph has changed.
- New solution is scheduled and completed
- C# client pushes change to custom Rhino-like object to the user’s current stream
- Client viewer detects change and is able to intelligently stream in new geometry/remove old geometry
- Javascript SDK methods like v.applyFilter or v.colorBy allow me to make client-side modifications based on selection/visibility
I do get the sense that I’m missing a few important concepts. But if even a fraction of this is accurate, I’m beyond floored and excited. More than happy to contribute towards any extra bits I might need that are helpful.
The main questions are:
- How accurate/possible is this?
- Where should I start, since I’m 100% new to Speckle?
I have follow-up questions about authentication and how diffing might work, and will continue reading/poking around. But my first understanding really does sound too good to be true and I wanted to check in first. Greatly appreciate any guidance. 
 (suffice to say both
(suffice to say both