It’s been four months since the structural object kit has been released which means that it’s time for a review of the objects. Come out to discuss with me and @jenessa.man , @d.naughton about the structural objects classes and review points for the structural object classes.
Possible points of discussion include:
Element Release (currently we’re using restraints for releases as well)
Come out again to discuss with me and @jenessa.man and @d.naughton about the structural object classes and review points for the structural object classes.
I’ve been using SAF for a SCIA converter. There are some discrepancies in how the structural data is organized, and SAF itself is still under development as well. It nevertheless is a good source of inspiration.
As I’m not sure I’ll be able to attend the (whole) meeting, I took the liberty to write down some concerns and ideas that could possibly be discussed:
About results:
If it does not yet exist, I think there is a need to document Speckle LCS and sign conventions (example 1, example 2)
ResultSetAll object currently holds a single ResultSet1D, ResultSet2D etc. Would it be better to make each of these properties hold a List of ResultSet1D, 2D, Nodes etc instead? This allows to split the ResultSet objects per LoadCase for example (stored in the resultCase property of the Result object).
Better to use conventional short-hand names for Result1D, 2D, … object properties (N, V, M, u)? Or are these less conventional than I think they are?
About Grasshopper connector (@AlanRynne):
Are there other people interested in making analytical models from scratch or editing them with Grasshopper? I’m experiencing several things that currently makes this impractical (certainly for non-expert Grasshopper users):
Huge amount of schema components with all identical icons;
Many redundant object input and output property values > Is it possible to hide the unused ones in the Grasshopper components?
Generic string representations > Is it possible to use an object’s Name property, if available?
This has been brought up in the past… but designing 100+ meaningful icons is a task we’re not willing to undertake at this moment, but as always we’re open to suggestions! Not making any promises here… but we’d definitely consider coordinating with any community member that would like to take this on (not a small or simple task though…)
It has also been previously suggested to change the yellow bg color for a different one based on category. I’m open to this, but that wouldn’t really solve the problem.
The way it currently works, it’s not possible. There is no way for us to know if a value is null because you didn’t set it, or if it was intentionally set to null.
If a user has a property that they set to null, and it doesn’t appear upon expanding, that would be even more confusing than having extra properties.
I could be convinced to add a right-click menu option to skip outputs that are entirely null, but that’s easier said than done
The reason these properties do not appear on the schema nodes is because these are generated using the class’ constructor (which was designed for creating valid instances with the minimum information necessary). But most of the time, the object model contains more detailed props that are used by (at least) some of the connectors that consume this classes.
This one is certainly doable, I’ll squeeze it in for next week so it can be released on 2.8
As for this one… I fear I’m not the most qualified to say how much (or not) these nodes are being used but I suspect they’re mostly used by a few advanced users.
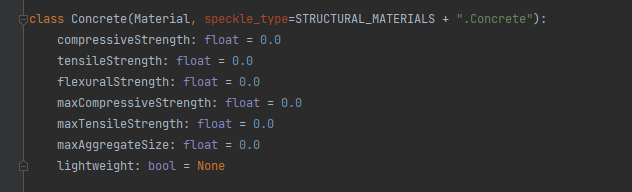
I have a question regarding the difference between the speckle-sharp and speckleypy. As you can see from the pictures below. The attributes namings are different between ‘maxCompressiveStrength’ and ‘maxCompressiveStrain’, ‘maxTensileStrength’ and ‘maxTensileStrain’. Could you take a look to check the reason behind the difference? Thanks!
we did start a recording but it didn’t get saved for some reason.
But here’s the meeting notes:
Structural Material Renaming - Approved to rename objects namespace to be Structural Material to avoid conflict with Built Materials
Management of Section Profiles and Properties - To take a hybrid approach of trying to match profiles initially by names then building section profiles from outline if sections aren’t found in (Revit/BIM software)
Results - Will still be kept separate for now but discussion of using a blob storage API to store them so there’s a faster access to all of the Results
Re :Kelvin discussion topics
Speckle LCS and Sign Convention - to be clarified in documentation
ResultSetAll - Approved to hold a list of ResultSet1D
Short hand conventions - not approved due to clarity
Thanks @AlanRynne for your reply and thanks @Reynold_Chan for considering my questions and sharing the conclusions.
I’ll let you know if I ever have too much spare time on my hands.
Indeed, a hybrid solution like this could be a good compromise. Apart from the context menu button to remove null outputs, perhaps you could also use the VariableParameterComponent interface to allow the user to manually remove any unuseful output. Perhaps it’s simpler to implement?
There are several technical issues with this though:
If we were to allow for automatic removal of null values, we’d need to know in advance before creating the outputs. This may be a bit tricky, as the conversion happens after the outputs are created, but may be solvable.
Allowing for user’s to remove specific parameters seems dangerous… The expand speckle object doesn’t know what it’s going to get (and shouldn’t), and it figures out the outputs “on each run”. So any outputs that were removed would reappear once you press F5.
On the other hand, if we try to remember the outputs a user has selected to “omit”, should we omit them too if the output changes completely? Consider this case:
You have a list of custom speckle objects that contain a section property that, in this particular case, is always null, so you hide it. Now you connect that same node to a list of completely different objects that have the same section property, but this time it’s not null. Should we keep the “omit” selection for the user, even though it’s clear that now you’re missing info?
Honestly, if you just need a bunch of keys from an object, you should just use GetObjectKeys to find them and then Object value by key to grab the ones you need. The fact that some properties are unused does not mean they are not there And I fear the logic of the expand node will get super weird for the average user if we start adding all this to it.
Hi Alan,
Ok, I get it, the component is already very dynamic and super complicated at the moment, best not to add to it. Thanks for clarifying and sharing your thoughts!
 Feburary 9th, 2022
Feburary 9th, 2022 4-5PM GMT
4-5PM GMT https://meet.google.com/pss-auqo-zpx
https://meet.google.com/pss-auqo-zpx