Hello everyone,
I’m writing to share a Python code I’m testing to create a page that integrates all my Speckle streams and, at the same time, allows me to interact with the branches through an OpenAI ChatGPT chat to query branch data.
You can find the Python code below, but to make it work, you’ll need some libraries and an OpenAI account with spendable tokens for the chat.
The necessary libraries are as follows:
- streamlit
- specklepy
- pandas
- pandasai
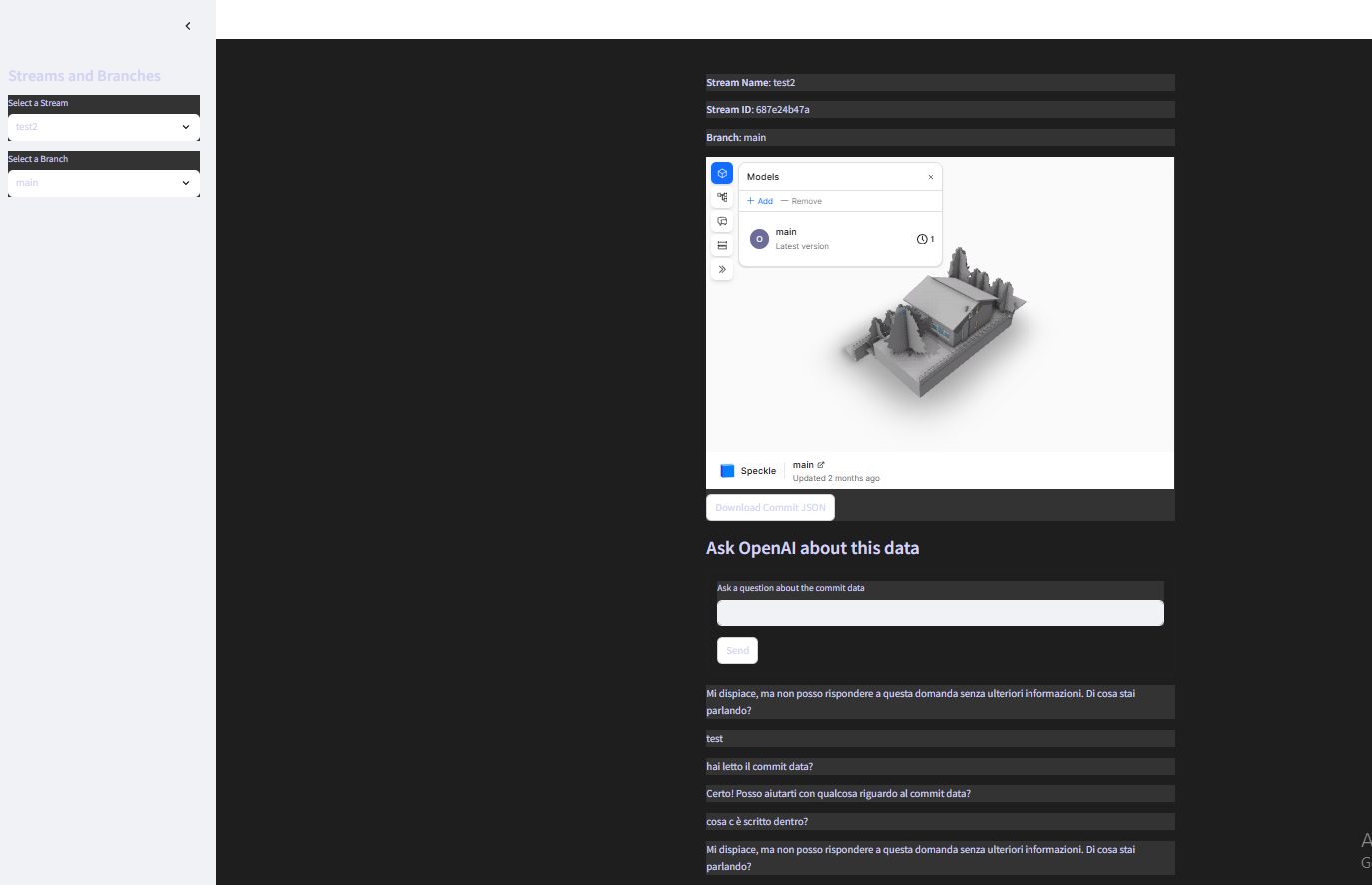
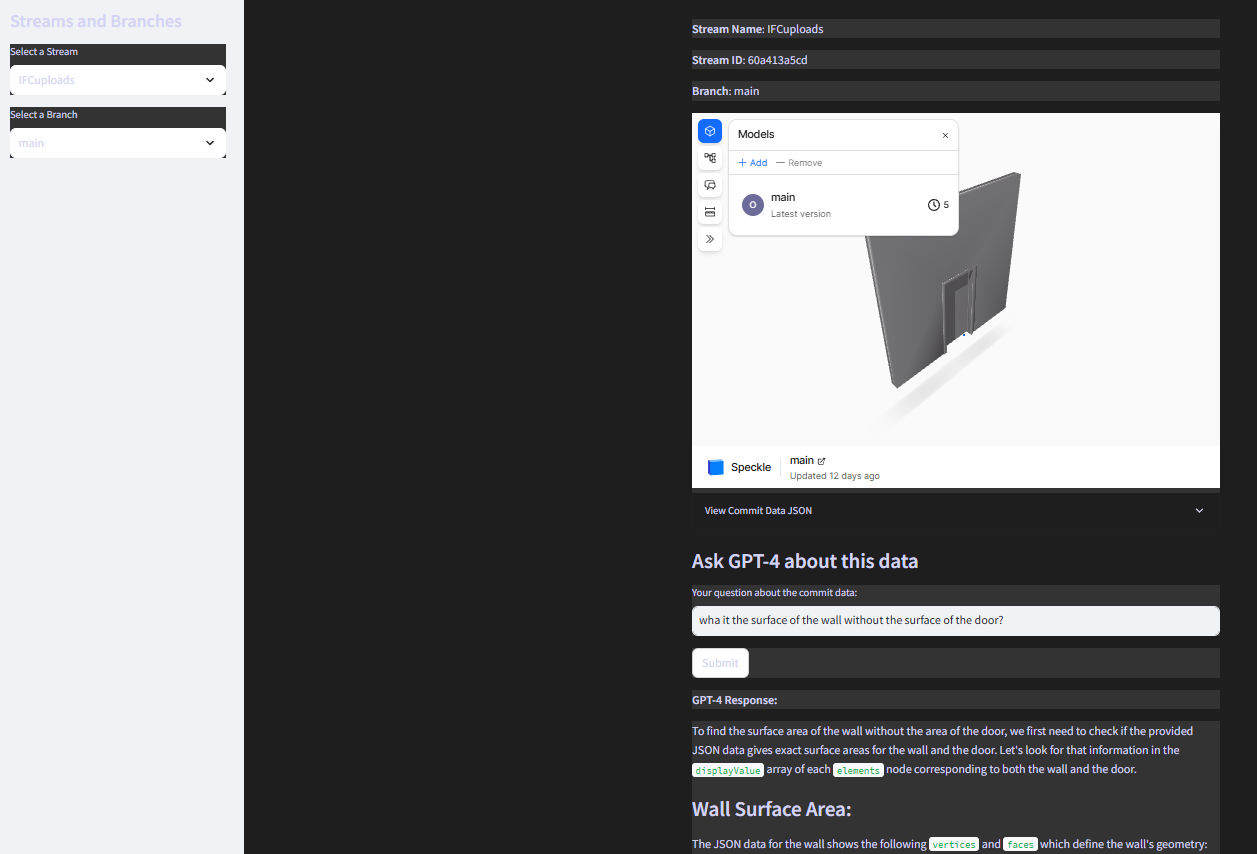
The problem I’m currently encountering is that, although the commit data seems to be correctly sent to OpenAI and the chat indicates that the data is interpretable, during the conversation, the chat says that the data is actually unavailable.
Can anyone help me correct this part so that, when the button is clicked to send the commit data to OpenAI, the data is actually used by the chat?
Thanks
import streamlit as st
from specklepy.api.client import SpeckleClient
from specklepy.api import operations
from specklepy.transports.server import ServerTransport
from specklepy.objects.base import Base
from specklepy.serialization.base_object_serializer import BaseObjectSerializer
import json
import io
import openai
# Set OpenAI API key and organization
openai.organization = "XXXXXXXX"
openai.api_key = "XXXXXX"
# Dark theme styling
st.markdown(
"""
<style>
body {
background-color: #1e1e1e;
color: #d3d3f3;
}
.stApp {
background-color: #1e1e1e;
}
.stTextInput, .stButton, .stSelectbox, .stDownloadButton, .stMarkdown, .stInfo {
color: #d3d3f3 !important;
background-color: #333333 !important;
}
.stAlert p {
color: #d3d3f3 !important;
}
h1, h2, h3, h4, h5, h6, p, div {
color: #d3d3f3;
}
</style>
""",
unsafe_allow_html=True
)
# Function to retrieve all streams associated with the account
def get_all_streams(token):
client = SpeckleClient(host="https://app.speckle.systems")
client.authenticate_with_token(token)
streams = client.stream.list()
return [{"name": stream.name, "id": stream.id} for stream in streams]
# Function to retrieve all branches of a stream
def get_all_branches(client, stream_id):
branches = client.branch.list(stream_id)
return [{"name": branch.name, "id": branch.id} for branch in branches]
# Recursive serialization function using BaseObjectSerializer
def serialize_data(data):
serializer = BaseObjectSerializer()
if isinstance(data, Base):
_, obj_dict = serializer.traverse_base(data)
return obj_dict
elif isinstance(data, list):
return [serialize_data(item) for item in data] # Recursively serialize list items
elif hasattr(data, 'items'):
return {k: serialize_data(v) for k, v in data.items()}
elif hasattr(data, '__iter__') and not isinstance(data, str): # Handle iterable Collections
return [serialize_data(item) for item in data]
else:
return data # Return the data if it’s already JSON serializable
# Function to get commit data as JSON, ensuring all objects are serialized
def get_commit_data_as_json(client, stream_id, branch_name):
try:
transport = ServerTransport(client=client, stream_id=stream_id)
branch = client.branch.get(stream_id, branch_name)
if branch.commits.totalCount == 0:
st.warning(f"The branch '{branch_name}' has no commits.")
return None
commit_id = branch.commits.items[0].referencedObject
commit_data = operations.receive(commit_id, transport)
# Serialize commit data to JSON-compatible format
commit_data_serialized = serialize_data(commit_data)
return commit_data_serialized
except Exception as e:
st.error(f"Error loading commit data for branch '{branch_name}': {e}")
return None
# Function to reduce JSON size by extracting only key data points
def reduce_json_data(data, max_keys=50):
if isinstance(data, dict):
return {k: reduce_json_data(v, max_keys) for i, (k, v) in enumerate(data.items()) if i < max_keys}
elif isinstance(data, list):
return [reduce_json_data(v, max_keys) for v in data[:max_keys]]
else:
return data
# Function to stream OpenAI Chat Completion response
def stream_openai_response(messages):
response_container = st.empty()
full_response = ""
stream = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.get("content") is not None:
content = chunk.choices[0].delta["content"]
full_response += content
response_container.markdown(full_response)
return full_response
# Chat history and initial JSON context
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = []
if "initial_context" not in st.session_state:
st.session_state["initial_context"] = None
# Speckle token and client initialization
speckle_token = "XXXXXXXXXXX"
try:
client = SpeckleClient(host="https://app.speckle.systems")
client.authenticate_with_token(speckle_token)
streams = get_all_streams(speckle_token)
# Sidebar selection for streams and branches
st.sidebar.title("Streams and Branches")
selected_stream = st.sidebar.selectbox("Select a Stream", streams, format_func=lambda x: x['name'])
st.session_state["selected_stream"] = selected_stream
branches = get_all_branches(client, selected_stream['id']) if selected_stream else None
if branches:
selected_branch = st.sidebar.selectbox("Select a Branch", branches, format_func=lambda x: x['name'])
st.session_state["selected_branch"] = selected_branch
if st.session_state["selected_stream"] and st.session_state["selected_branch"]:
st.write(f"**Stream Name**: {st.session_state['selected_stream']['name']}")
st.write(f"**Stream ID**: {st.session_state['selected_stream']['id']}")
st.write(f"**Branch**: {st.session_state['selected_branch']['name']}")
# 3D Viewer iframe
viewer_url = f"https://app.speckle.systems/embed?stream={st.session_state['selected_stream']['id']}&branch={st.session_state['selected_branch']['name']}&c=%7B%7D"
st.markdown(f'<iframe title="Speckle 3D Viewer" src="{viewer_url}" width="100%" height="500" frameborder="0"></iframe>', unsafe_allow_html=True)
# Fetch commit data
commit_data = get_commit_data_as_json(client, st.session_state['selected_stream']['id'], st.session_state['selected_branch']['name'])
if commit_data:
# Prepare JSON for download
reduced_data = reduce_json_data(commit_data)
commit_data_json = json.dumps(reduced_data, indent=4)
json_bytes = io.StringIO(commit_data_json).getvalue().encode()
json_filename = f"{st.session_state['selected_stream']['name']}_{st.session_state['selected_branch']['name']}_data.json"
# Download button outside form
st.download_button(
label="Download Commit JSON",
data=json_bytes,
file_name=json_filename,
mime="application/json"
)
# Button to send commit data context to OpenAI in the background
if st.button("Send Data to Chat"):
st.session_state["initial_context"] = commit_data_json
st.session_state["chat_history"].append({
"message": "Here is the full commit data for your reference.",
"is_user": False
})
st.write("Data sent to chat context. You can now ask questions about it.")
# OpenAI Chat for Q&A
st.subheader("Ask OpenAI about this data")
with st.form(key="chat_form", clear_on_submit=True):
user_input = st.text_input("Ask a question about the commit data")
submit_button = st.form_submit_button("Send")
if submit_button and user_input:
# Add the user question to chat history
st.session_state["chat_history"].append({"message": user_input, "is_user": True})
# Prepare OpenAI messages with full chat history and initial context
def prepare_openai_messages(chat_history, initial_context, user_input):
messages = [{"role": "system", "content": "You are an assistant that answers questions based on JSON data."}]
if len(chat_history) == 1:
messages.append({"role": "user", "content": f"Here is the data context: {initial_context}"} )
for entry in chat_history:
role = "user" if entry["is_user"] else "assistant"
messages.append({"role": role, "content": entry["message"]})
messages.append({"role": "user", "content": user_input})
return messages
messages = prepare_openai_messages(st.session_state["chat_history"], st.session_state["initial_context"], user_input)
response = stream_openai_response(messages)
st.session_state["chat_history"].append({"message": response, "is_user": False})
# Display chat history
for chat in st.session_state["chat_history"]:
if chat["is_user"]:
st.write(f"**User**: {chat['message']}")
else:
st.write(f"**Assistant**: {chat['message']}")
except Exception as e:
st.error(f"Error retrieving streams or branches: {e}")