Hi @dimitrie,
I want to know that how the stream and object structure are different compared to speckle 1.0. We are developing data structure based on it. It will helpful if you provide the details.
Hi @dimitrie,
I want to know that how the stream and object structure are different compared to speckle 1.0. We are developing data structure based on it. It will helpful if you provide the details.
Hi @Ritesh_Solanke! I’m simple question, long answer 
In 2.0, Speckle supports pretty much any kind of structure for data. Some examples:
On the receiving end, what we do, is we iterate through this structure and do whatever action we need to. For example, let’s assume the following data structure coming from Grasshopper, with a bunch of elements:
var commit = new Base();
commit["levelOne"] = new List<Base>() { some walls, some floor slabs, some furniture, etc. }
commit["levelTwo"] = new Dictionary<string, object>() { [ "levelTwo-LeftWing" = a list of objects], [ "levelTwo-CentralAtrium" = a different list of objects] }
When received in Revit, we initially flatten the structure and extract the objects we can convert to Revit; then we convert said objects via the kit conversion routines. In Rhino, we have a similar approach: we traverse the commit, and as we find convertable objects, we create them into the current Rhino document on nested layers that replicate the commit structure:
For the 3d viewer, we do exactly the same thing; we always traverse the data structure and we convert it to buffer geometries that we can later display in threejs:
There is no given or fixed structure of a commit - see it like everybody organises their code project files in different ways. In order to operate on, or with, objects in Speckle you have to traverse the commit data structure and operate on it accordingly:
map and reduce` operation - this can be very powerful and memory efficientthank you @dimitrie for explanation. We are right now focusing on the Revit, where you are grouping the similar type of elements in current version, which is not their in previous version. I would like to know are making any structural changes in tessellated geometry structure in 2.0.
Not really, though it would be good to check the classes out. Meshes stay the same!
If I am correct the mesh data structure won’t have any changes. But if you remember we have discussed that you can add single instance for repeating instance and reduce the mesh size. Have you added that in 2.0.
Unfortunately not yet - but this does make it easier for development purposes ![]() It’s a good optimisation, but quite complex to enable reliably. We’re saving off much more by using compression and caching, so we’ve put it on the backburner for now.
It’s a good optimisation, but quite complex to enable reliably. We’re saving off much more by using compression and caching, so we’ve put it on the backburner for now.
you mean the JSON data output for mesh will be same ? will it affect due to change in database to Postgres from mangodb ?
Morning @Ritesh_Solanke! Yep, meshes stay the same. Here’s an example. You’ll notice the good old vertices and faces array. As a reminder, the face array is structured as
[ faceType, vertexIndex_0, vertexIndex_1, vertexIndex_2, (vertexIndex_3) ]
where faceType can be 0 for triangles and 1 for quads.
The main thing to keep an eye out is the chunking of large arrays that we’ve introduced recently. Here’s our internal research doc re why we needed this. The .NET and Python SDKs handle this for you on deserialisation.
You have changed storage of streams and objects from mongodb to postgres for 2.0 right ? So I want to understand how you are keeping the data in tabulated format. If possible can you share the doc or code base where I can get better clarity.
Morning @Ritesh_Solanke! Sure, here’s the actual migrations that create the objects tables:
The decomposition logic explains more in depth how things are structured, so it can be considered “required” reading to understand the approach in detail.
hey @dimitrie If I understand correctly there is no stream in 2.0, then how you are going to handle the versioning is it at object level ?
Wait up, streams exist! They’re much more like git repos now though. @izzylys did a nice write up here re the basic concepts (streams, commits, branches, etc)
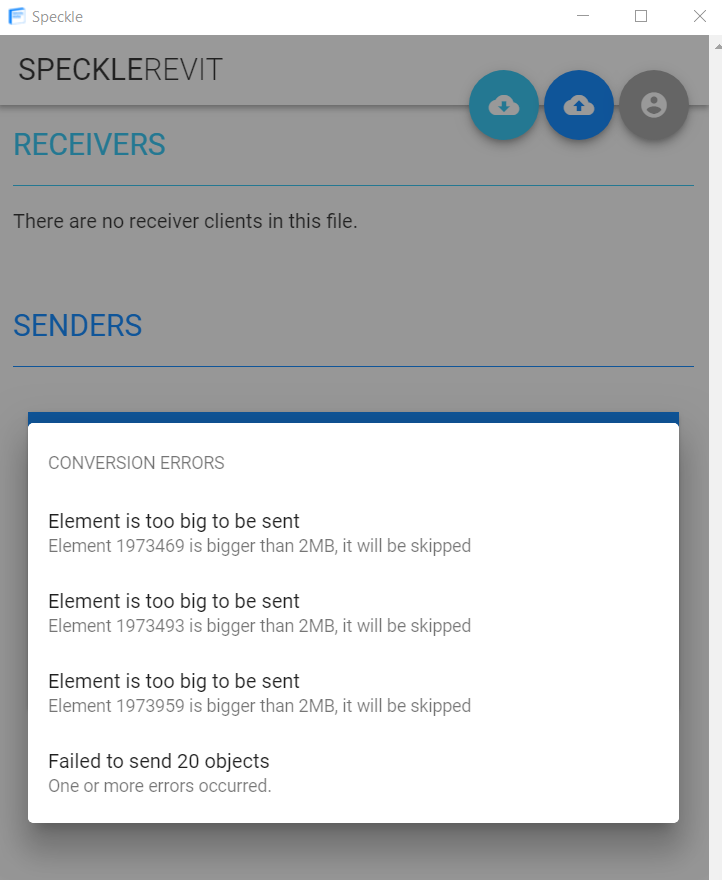
hey @dimitrie ,
I am using the speckle 1.0 where I have noticed error like “if file size is exceed 2MB the elements are skipped” we have noticed that some of elements are missing. Is this issue is fixed in 2.0 !
I have attached error message image for your reference.
MicrosoftTeams-image (2)|410x500
Yes it is! Though i am quite skeptical of those 2mb - can you let us know what those elements are? Usually it’s an out-of-control mesh for a simple extrusion…
{kind=link}