Preamble
Good morning everyone in the @Speckle_Insider! The previous post covered the new base Speckle object. This one covers an equally important concern, namely how Speckle deals with the structure and composition of design data.
Blobs and Trees
In 1.0, Speckle has been focused mostly on storing efficiently flat lists of objects - geometry and metadata. These objects could have any amount of nesting in and of itself, but this would not be reflected in the storage layer (they would, ultimately, be “json blobs” grouped together under a stream).
This scenario worked well, as it’s quite similar to the way most CAD applications expose “scene” information. Nevertheless, as you can well imagine, design data is relational: built elements link to each other. How do they relate to each other? Well, it depends: there’s no canonical way of structuring data.
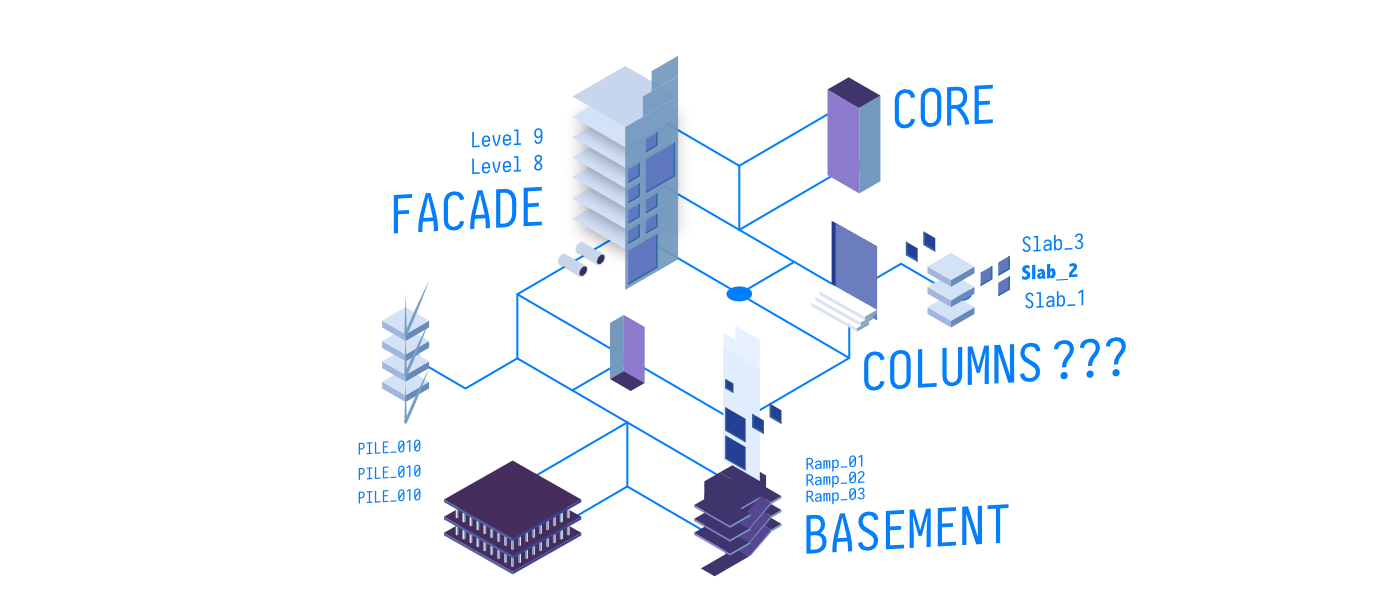
For example, a Site object may contain one or more Building objects. These, in turn, may contain one more Levels, and each of these Levels may contain some Walls, Floor and Beam elements. Or, those Building objects may each individually reference the same Site. Within the Building object, there’s all the Walls and Beams, and each of them, rather than being grouped under a Level, they individually reference a specific Level.
In order to solve this, I’ve taken a good look at how git, the ubiquitous version control system, works. Git operates with two object types: blobs and trees. Blobs represent files, and an important characteristic is that they are immutable - just like objects are in Speckle. Trees represent folders, and they are used to track the hierarchy of the folder structure of your repository.
Spoilers 🤫
If you think this analogy hints to more, you’re right: Speckle is becoming a fully fledged version control system for design data. Keep an eye out
As opposed to Git, that deals with data structured on your hard drive, Speckle deals with data structured in memory. In Speckle, an object is, at the same time, both a blob (data) and a tree (its subcomponents). There are two separate, yet interweaved, problems (and their corollaries) that I’ll now address:
- How to decompose an object? (Corollary: how to recompose an object?)
- How to serialise, transport and store that decomposed object? (Corollary: how to retrieve and deserialise an object?) - this will be tackled in a follow up post!
Decomposing
There is no right or wrong way to structure design data. Different applications operate with different models, different use-cases require different hierarchies, different disciplines and professionals operate with differently structured ontologies.
Speckle now has a mechanism by which, in the process of specifying an object - either via a strongly typed Kit, or via dynamic properties - developers (and end-users) can decide what gets decomposed and what doesn’t.
Strongly Typed Detachment
It works, in the case of strongly typed properties, by adding the Speckle specific attribute [Detach] on the properties you want to store as references, rather than within the object itself.
For example, let’s take an imaginary example:
public class Building : Base {
[Detach] // this attribute tells Speckle to store the value of the Site separately.
public Site Site { get; set; }
public List<Level> Levels { get; set; }
public Owner { get; set; }
}
public class Level : Base {
public double height { get; set; } = 3.2;
public double baseElevation {get; set; } = 0;
[Detach]
public List<Base> Elements { get; set; } // The actual walls, floors, columns, etc.
}
// Define a site globally
var mySite = new Site();
// Reference the same site in both buildings.
buildingA.Site = mySite;
buildingB.Site = mySite;
When an instance of the Building class gets saved, the Site will be stored separately. If two Buildings share the same Site, it will be stored only once, and each instance of the Building class will hold a reference to the same Site.
In our example, each Level can hold, in a detachable property, all its walls, beams, ducts, pipes, furniture, and other built elements. Consequently, each of these elements will be individually accessible from the storage layer, and will maintain topological unity. Why is this important? Let’s imagine a building with a series of levels separated by floor slabs. The slab between two levels pertains to which level: the bottom one, or the top one?
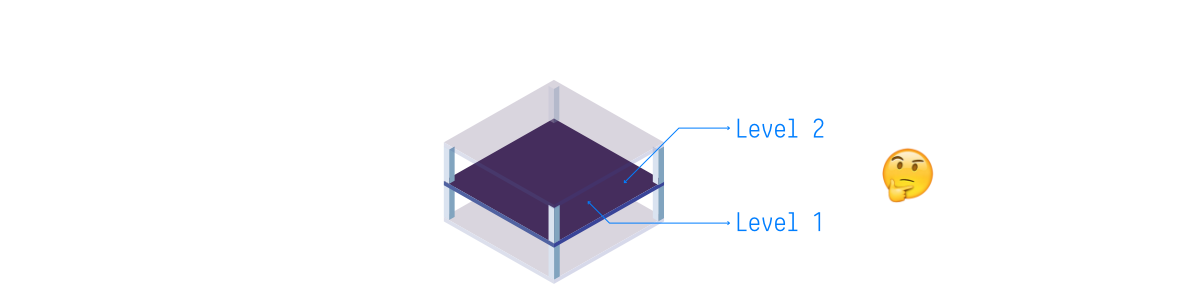
Dynamic Detachment
Let’s illustrate this through an example that also demonstrates how dynamically added properties can be detached. We’ll assume that we will dynamically set topSlab and bottomSlab properties to each level in our imaginary object model:
// We're grossly simplyfing in this example. Here are our two building levels:
var level_1, level_2;
// The philosophical slab instance. Does it belong to level 1 or level 2?
var slab_between_1_and_2 = new Slab();
// Well, it belongs to both! Notice the "@" characther at the beginning of
// the dynamic property assignment - it's the Speckle convention for "detaching"
// dynamically added properties.
level_1["@topSlab"] = slab_between_1_and_2;
level_2["@bottomSlab"] = slab_between_1_and_2;
Because we’ve prepended the property name with an “@” symbol, Speckle will now “detach” it. Consequently, once stored, both level one and two will now hold a reference to a single slab! Beyond storage efficiency - the slab is only stored once - this approach gives us the freedom to structure data however is best and, simultaneously, query, slice and dice it however we need to.
For example, let’s assume you need to do a quantity takeoffs:
- For each each individual level: specify the total surface area, including walls, ceilings, etc. Solution: simply retrieve each level individually!
- For the whole building: calculate the total volume of concrete that goes into the slabs. Solution: just query the building object for all the slabs!
Similarly, imagine you’ve written a script that does environmental analysis on a given level. The level can now be retrieved in its entirety - without juggling around to bring in the level above it too, just to get the ceiling out. Once the results are calculated, they can be stored in a detachable property on that specific level (e.g., level_1[@"solarComfortMeshWithColours"] = analysisResultMesh;). Later down the line in your workflow, one can could query for all the “solarComfortMeshWithColours” objects individually for each level, or, if needed, for the whole building.
Recomposing
Recomposition of an object happens within the deserialisation process, and it’s tightly integrated with the transport layer. The process, on the surface, is deceivingly simple. When you ask Speckle to receive a specific object, the process is as follows:
- Speckle retrieves said object’s “blob” (actually a JSON string representation of it),
- Next up, Speckle retrieves at all the reference tree of this object,
- Speckle proceeds to deserialise and re-compose the parent object, inserting in the place of references the actual referenced object.
Wether or not this sounds complicated, the exposed API is actually rather simple and the end result is that a decomposed object, when received back, will be identical with the original one - with all its parts in place ![]()
Conclusion & What’s Next
End users and developers can now, in Speckle 2.0, productively control the way they structure their design data through the decomposition mechanism. From the point of view of the future Speckle connectors, this will enable us to expose object model flexibility in a more elegant way than before to end users. As developers, Speckle gives you another powerful API on top of which you can scaffold your digital automation workflows.
More importantly, this allows you to store arbitrary data structures (scaffolded on top of a Base) with Speckle, without paying any penalties: Speckle deals equally well with flat and nested data.
So, what’s next?
So far, I have mentioned a “transport layer” and “storage layer” quite a few times. These demarcations underpin yet another important part of the new Speckle 2.0, and they control how and where design data is being stored and retrieved (“transported”). They’re tackled in the following post - so keep your eyes peeled ![]()
 Something like that does apply though.
Something like that does apply though.
