Hey all,
I ran into some issues with chunking/ sending / receiving larger files.
-
Objective:
Receive large files/data from a commit thats assambled with referenced objects in grasshopper -
Issue:
After a lot of trying I managed to send large matrices (numbers and metadata, ca. 30MB each) to speckle by:
- manually chunking the matrices
- sending individual chunks of rows to speckle
- collect and reference object ids of chunks to “container” speckle object (representing the complete matrix)
- referencing the container objects to another container object that holds references to all matrices and their corrosponding chunked rows.
- send this container as a commit to speckle
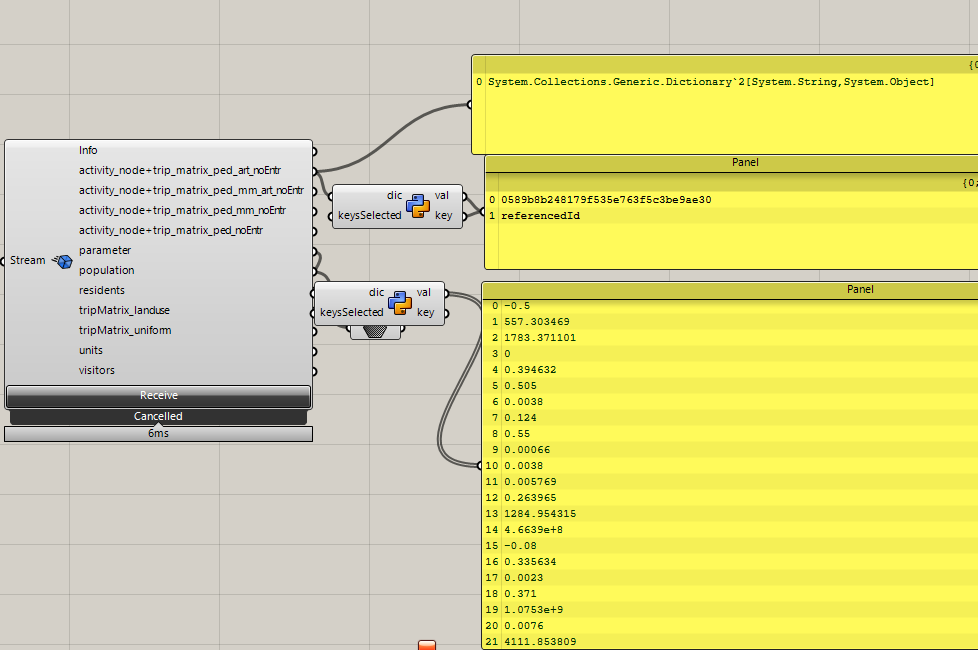
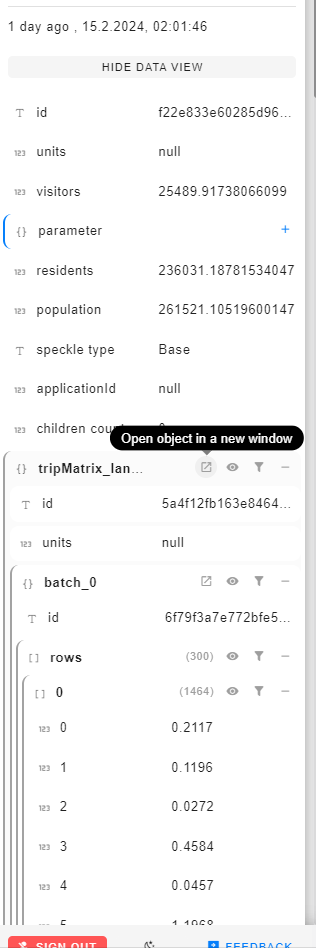
On the webviewer this works, I do not only see the reference ids but the actuall data ( there is a icon indicating when the data is referenced). This works as intended. However, if i fetch that branch and commit in grasshopper I only get the referenced objectids.
My goal is to fetch the complete object/data and parse it back to its original form using python in gh.
-
question
Is there perhaps a smarter and simpler way to achieve the goal of sending and receiving larger objects from gh/python to gh/python ? -
Example:
attached are two images of how the commit data looks in grasshopper and in speckles webviewer.
-
python code for chunking
def send_row_bundle(rows, indices, transport):
bundle_object = Base()
bundle_object.rows = rows
bundle_object.indices = indices
bundle_id = operations.send(base=bundle_object, transports=[transport])
return bundle_id
def send_matrix(matrix_df, transport, rows_per_chunk):
matrix_object = Base(metaData="Some metadata")
batch_index = 0 # Maintain a separate counter for batch indexing
# Bundle rows together
rows = []
indices = []
for index, row in matrix_df.iterrows():
rows.append([round(r,4) for r in row.tolist()])
indices.append(str(index))
if len(rows) == rows_per_chunk:
bundle_id = send_row_bundle(rows, indices, transport)
# Set the reference to the bundle in the matrix object using setattr
setattr(matrix_object, f"@batch_{batch_index}", {"referencedId": bundle_id})
rows, indices = [], [] # Reset for the next bundle
batch_index += 1 # Increment the batch index
print( str(rows_per_chunk) +" rows has been sent")
# send the last bundle if it's not empty
if rows:
bundle_id = send_row_bundle(rows, indices, transport)
setattr(matrix_object, f"@batch_{batch_index}", {"referencedId": bundle_id})
# Send the matrix object to Speckle
matrix_object_id = operations.send(base=matrix_object, transports=[transport])
return matrix_object_id
# Main function to send all matrices and create a commit
def send_matrices_and_create_commit(matrices, client, stream_id, branch_name, commit_message, rows_per_chunk, containerMetadata):
transport = ServerTransport(client=client, stream_id=stream_id)
matrix_ids = {}
# Send each matrix row by row and store its object ID
for k, df in matrices.items():
matrix_ids[k] = send_matrix(df, transport, rows_per_chunk)
print("object: " + k + " has been sent")
#container object that will hold references to all the matrix objects
container_object = Base()
for k, v in containerMetadata.items():
container_object[k] = v
# reference matrix objects by their IDs in Speckle
for k, obj_id in matrix_ids.items():
print("obj_id", obj_id)
container_object[k] = obj_id
# Dynamically add references to the container object
for matrix_name, matrix_id in matrix_ids.items():
# This assigns a reference to the matrix object by its ID
# You might need to adjust this based on how your Speckle server expects to receive references
setattr(container_object, matrix_name, {"referencedId": matrix_id})
# Send the container object
container_id = operations.send(base=container_object, transports=[transport])
# use the container_id when creating the commit
commit_id = client.commit.create(
stream_id=stream_id,
object_id=container_id, # Use the container's ID here
branch_name=branch_name,
message=commit_message,
)