Hi folks, say someone has pushed up a very large and detailed model out of Revit, and all I’m interested in is the simpler stuff - bounding boxes, start and end points of pipes in this case. It’s both resulting in a big download and a big conversion time. The data is being used in a standalone dotnet app without access to a local cache transport.
There might already be a solution to doing this that I haven’t found or have forgotten is possible.
My instinct would be to implement a custom transport where CopyObjectAndChildren() checks for certain field names, and then either remove the fields from the object or locally replacing the children of said fields with stubs that don’t contain the mesh info instead of downloading them.
Broadly, I’m looking to only download stuff from a given commit that I need, without putting the onus on the revit user to be super specific about what they send up (and others will want to view and consume the meshes on the server).
Looking at it a little bit more deeply, I think there really is just that much data in each of these elements - 79000 objects with an average size of 130kb, most of it revit properties. In which case, I’m unsure about how to proceed - maybe the first step IS to post process the revit model onto another model branch, just with the data I care about, and then pull that down.
Hey Chris, this sounds like a classic case for pre-filtering at the data retrieval stage rather than post-processing everything locally. Given that your .NET app is running without a cache transport and you’re working with large, detailed Revit models, the best approach is to avoid pulling excess data in the first place.
The Speckle Way: Trigger[Web hook, automate, button press]→ GraphQL Filter → Processed Data - Publish new model (version)
Rather than trying to fix Speckle Connectors, modify transports, my first thought is also to consider leveraging a webhook-triggered filtering process.
Webhook Event: Trigger on New versions
When a version is made, a webhook event fires.
The payload only contains the project and model ID, keeping things lightweight.
GraphQL Query: Fetch Only What’s Needed
Using the webhook’s model ID,
Don’t retrieve the version as a whole
a custom GraphQL query retrieves just the elements you are interested in
process to extract bounding boxes & pipe start/end points. (Not all conversions add these so opportunities to make those missing )
Nothing else is downloaded—no unnecessary properties, no meshes.
Pushing the Optimised Model:
The extracted data is then pushed as a separate branch within Speckle.
Your .NET app can now consume only the lightweight branch, keeping downloads and processing time minimal.
⸻
Why This Works:
No extra burden on the Revit user—they don’t need to manually filter before sending. Speckle remains the SSOT—other users can still see and consume the full model. Your app stays efficient—only pulling what it actually needs.
⸻
Implementation Notes:
As you’re running on a dedicated Speckle server, you can set up this workflow with GraphQL + a simple script there is nothing Automate specific here, Just slight implementation differences.
whether it is a button press or a trigger doesn’t matter much my thought goes to trigger not only because I have automate on the brain but it does reduce the processing payload you need to do real time you can just consume a ready-made data source
Next gen connectors team, I believe are looking in some circumstances to limit. The amount of data pushed the advantage of course of starting things fresh, but that doesn’t help you now because you have a model to retrieve.
This keeps Speckle lean & flexible while letting you work at scale without unnecessary data overhead.
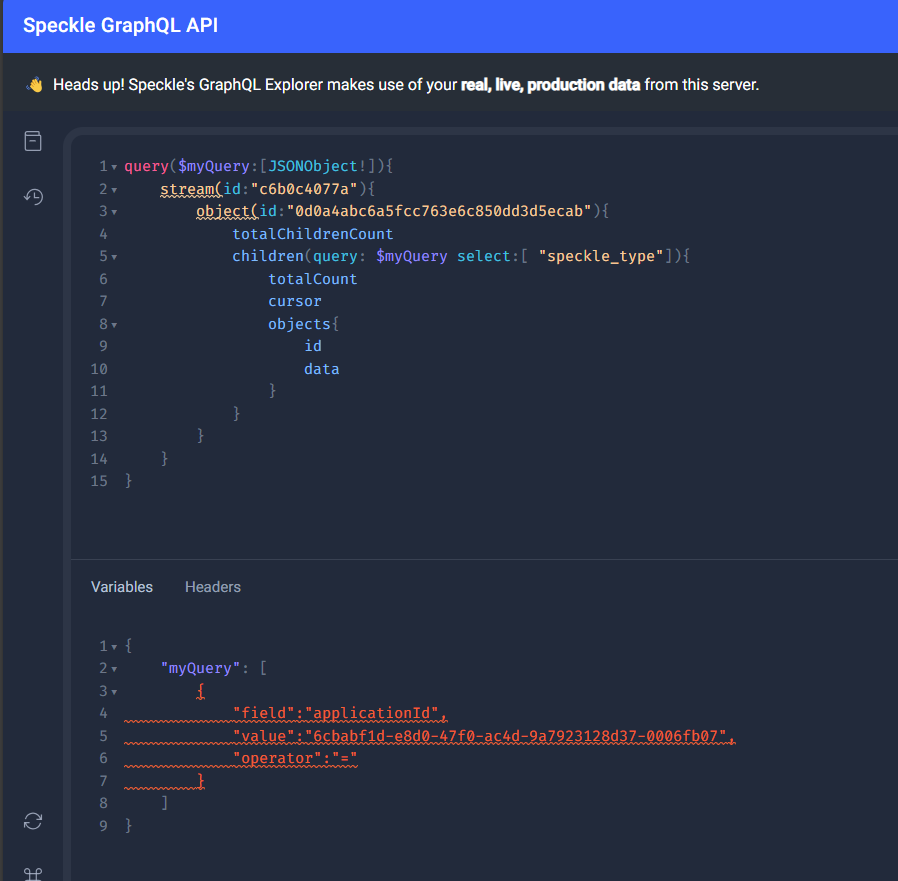
Ah, the trick I had missed was this: GraphQL API | Speckle Docs
I’d somehow never come across that you can do custom queries like this with graphQL. That should solve my problem! Thanks very much @jonathon, appreciate it
@jonathon just a note that there seems to be some kind of linting bug in the graphql on the front end - this is a valid query from your example on the server, which works when you run it, but shows as a bug expecting a jsonobject. (this is on Speckle GraphQL API)