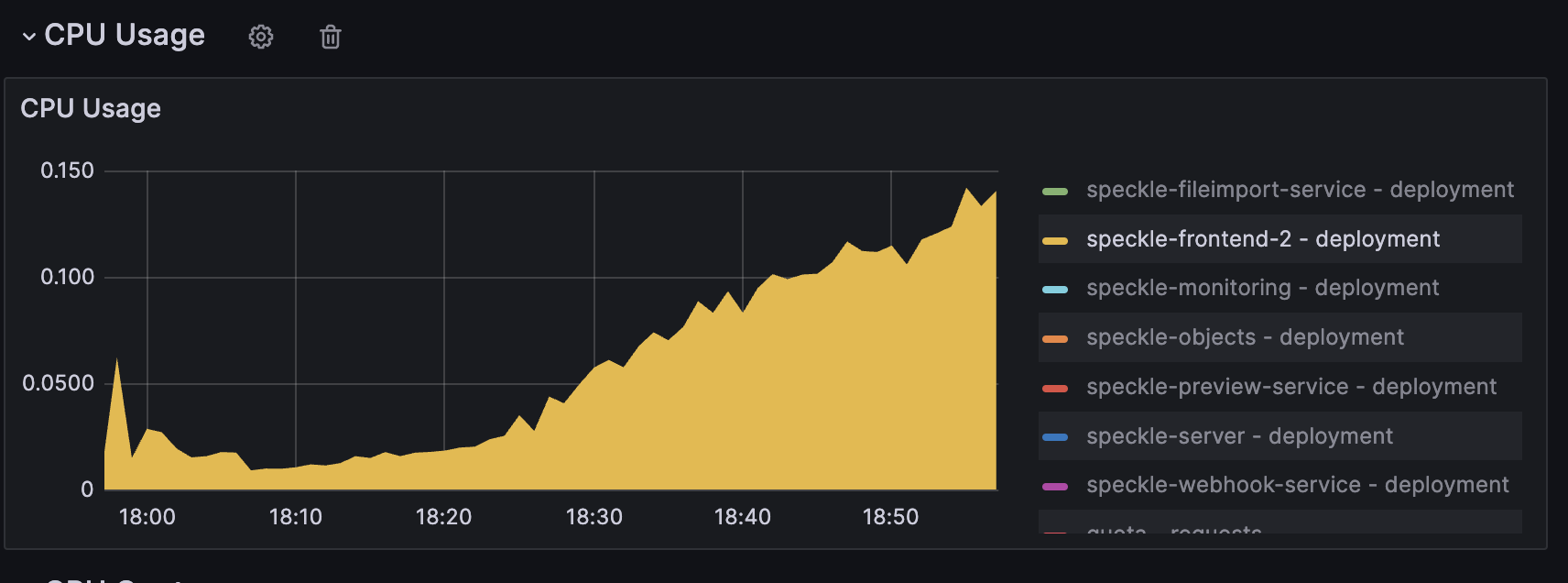
This is more to flag a potential issue than a request for help. I deployed 2.18.2 in my cluster and I’m seeing a steady rise in CPU utilization in the frontend-2 pods, but I don’t currently have any active users. Is anyone else having this issue?
This issue actually started last week (2/9) when I deployed a forked version of frontend-2 that incorporated some pre-release commits from the speckle-server repo. At first, I assumed I caused the issue with my modifications, but this issue is reappearing with a clean deployment of the 2.18.2 image (without any edits from me). The CPU utilization has been climbing steadily until it reaches the 1000m limit after about 2 hours.
It could be an issue I caused with my helm configuration, but thought I should flag it. Otherwise, I can track down the git refs corresponding to the merge where this issue started, if anyone else is seeing the same thing.
I resolved our issue by patching my fe-2 Deployment with the correct NUXT_REDIS_URL because my deployment couldn’t access my Secret. (I don’t even know if fe-2 actually uses the NUXT_REDIS_URL, but for whatever reason, my CPU utilization and memory consumption dropped to regular levels after I made the patch).
I haven’t had time to look into it any deeper than noting that it’s resolved.
I haven’t noticed a storage issue, but I haven’t been tracking it in my Grafana dashboard.
Looking at the logs of one of the fe2 containers, I saw a few ECONNREFUSED at port 6379 errors. I figured not being able to connect to a resource or not being able to cache effectively are at least plausible sources for accumulating CPU load. Since I hadn’t changed my env vars or secrets, I assumed it was a permissions issue (network policy or service account) preventing fe2 containers from seeing the secret. I didn’t have time to dig, so I just patched the NUXT_REDIS_URL with a fixed value … and the CPU load fell immediately.
Then today, looking at the fe2’s network policy, I saw the hanging text right above the only line relevant to Redis and it seemed like exactly the kind of thing that would prevent access to Redis.
Happy to send you the full log if there’s any need, but looking back at it now, I see it even says "@mt": "Redis error"
"err":{"type":"Error","message":"connect ECONNREFUSED 127.0.0.1:6379","stack":"Error: connect ECONNREFUSED 127.0.0.1:6379\n at TCPConnectWrap.afterConnect [as oncomplete] (node:net:1555:16)","errno":-111,"code":"ECONNREFUSED","syscall":"connect","address":"127.0.0.1","port":6379},"@t":"2024-02-12T20:29:53.848Z","@x":"Error: connect ECONNREFUSED 127.0.0.1:6379\n at TCPConnectWrap.afterConnect [as oncomplete] (node:net:1555:16)","@mt":"Redis error"}
Happy you found the issue relatively quickly, and thanks for providing this. I’m hoping your description will help anyone else in a similar situation in the future.
We can perhaps improve the readiness checks for frontend-2; the checks should verify the status of Redis, if enabled, before serving traffic.