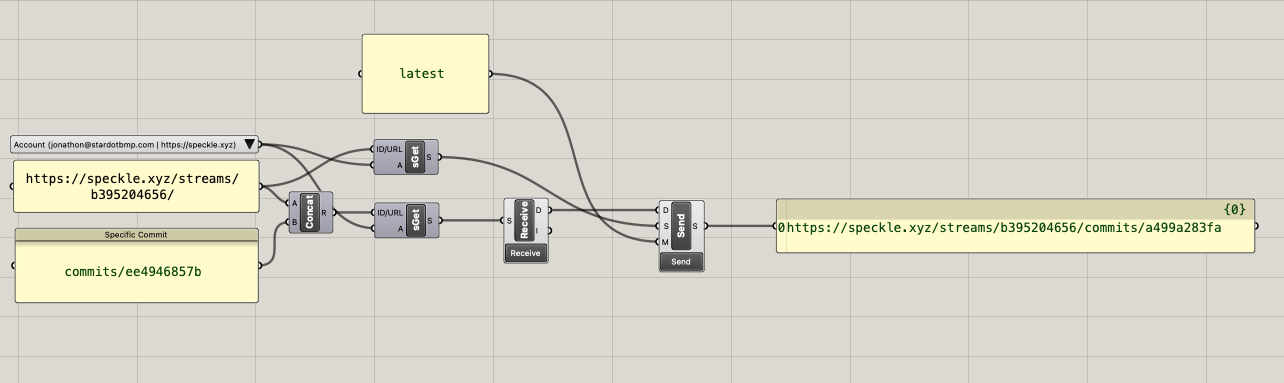
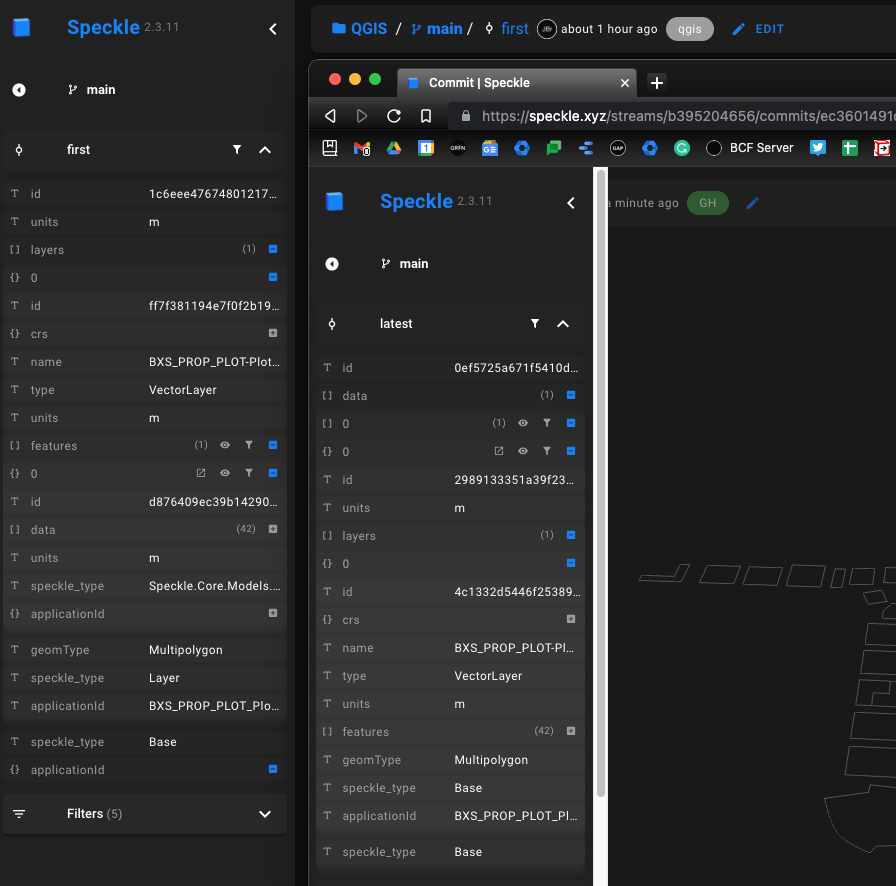
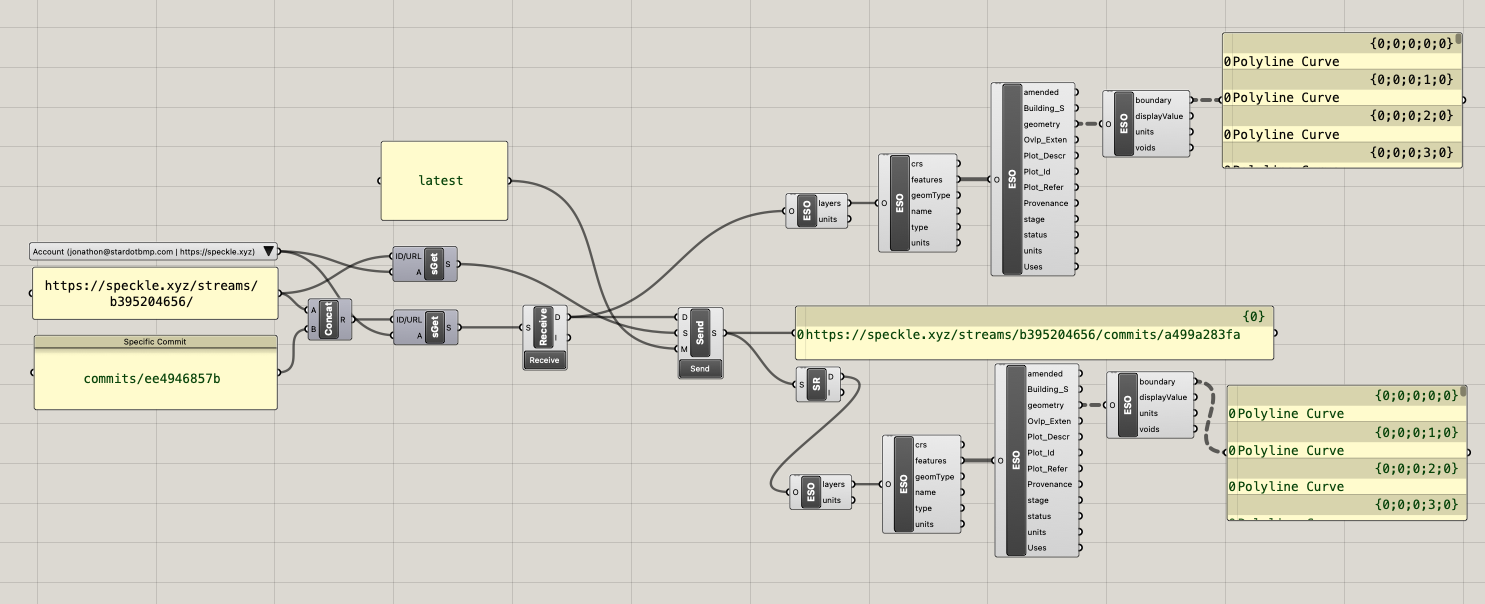
I actually had a more detailed question originally regarding atomic updates to deeply nested objects, but in reducing my test case I wondered about observed behaviour.
Q. Given the read-stream is ultimately the same, is this expected behaviour, a consequence of multi-app kits etc?
Q. Given this fluid data structure, what is the recommended methodology for updating a single child object within the tree to minimise diffs? Instead, is the single ‘root’ object replaced by default?
Q. The Bob, Mary & Sue multiplayer example has the resultant mappings as a separate branch. How does this pattern work with roundtripping data from source through analysis and back to the source? e.g. Revit to CAD to QGIS to Rhino > Revit
Q. When is the parents field triggered for commits?
Speckle works “only forward” and on a lossy interoperability principle. Basically, when you pull data from QGIS in Grasshopper, we adapt to Grasshopper’s ways as best as we can. When you send data out of Grasshopper it’s going to be ultimately differently structured than when it’s coming from QGIS (or replace QGIS with any other connector). The act of “baking” data inside a host app will adapt it to the app’s models.
I guess this answers also Revit to CAD to QGIS to Rhino > Revit question.
When we can, and not consistently currently. E.g., if you create a commit from gh with an instance of the sender component, sending again using that same instance of the sender component will create a parent-child relationship.
The whole diffing part happens in the background, so you shouldn’t really need to care about it! Think of speckle as storing object graphs, in which each single object gets its own unique hash. So if you change a leaf (sub-object) of the parent, the parent’s hash has to change as well.
We are, as always, really curious to the actual usecase - we might be missing something obvious when it comes to what you’re trying to do, and would be happy to enable it if it’s a blocker
Thank you. I think I knew a lot of this intuitively but on my 2022 mission of asking before rabbit holes, this was that.
The multiplayer case study is actually pretty descriptive of the pattern to deploy and no doubt there is something in the Speckle Manifesto pages that describes things as lucidly as you just did. I should read more.
Nominally, I suppose, a round-trip Revit to whatever and back to Revit could be achieved in a sense with a dynamo script built for specific use-case IF the original applicationId could be persisted as a passed parameter.
Revit > Script [applicationId → Revit:applicationId] > Analysis > Dynamo > Push QA data into objects
The specific use case I had in mind was to augment QA data into Revit objects where the analysis is performed outside of Revit. If Revit were better at displaying linked data then this obviously wouldn’t be a problem.