As you may have recently read, we have made a number of improvements to the file upload features in Speckle; such as supporting more file types and larger file sizes and improving our IFC file support.
In order to make these features possible we have made changes to Speckle server’s API. This will affect any developer who has made a custom integration to upload files to Speckle using the REST API path POST /api/file/:fileType/:streamId/:branchName?'.
If you are not developing against Speckle’s REST API or not self-hosting Speckle’s open source server, this will not affect you. These new features are already available on https://app.speckle.systems.
For the vigilant amongst developers using Speckle’s REST API, you may have noticed that since early July the POST /api/file/:fileType/:streamId/:branchName?' REST API endpoint has returned an additional Warning header in its response. This Warning header states that this endpoint is deprecated.
This endpoint is replaced by three separate operations, including two Graphql mutations. This new process allows much larger file sizes to be supported, and potentially allows these files to be uploaded faster than via the REST API. Below I will explain how to use the new methods in detail.
These new graphql mutations are available immediately on https://app.speckle.systems. They are also available for self-hosters, and further below we provide more details to make the new method work on a self-hosted Speckle server.
Instructions for developers
Firstly, the client must make an authenticated POST request to /graphql with the mutation fileUploadMutations.generateUploadUrl. Providing the projectId and the name of the file you wish to upload (filename) as inputs, the endpoint will return an url.
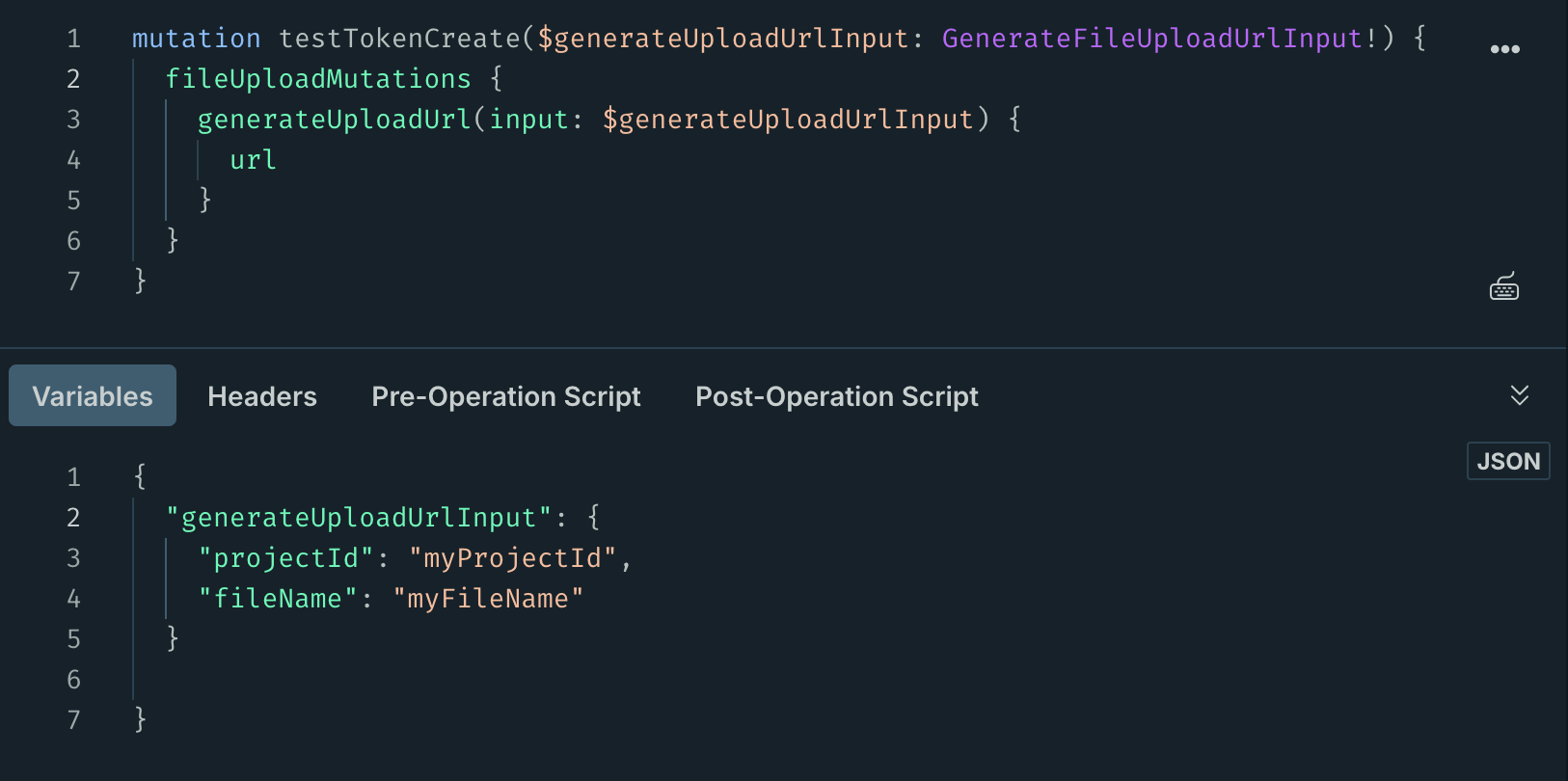
A PUT request should be sent to this returned url. The Content-type header should be set for this request, and should match the content type of the file being uploaded in this request body. This request will respond with details about the uploaded file, including its etag.
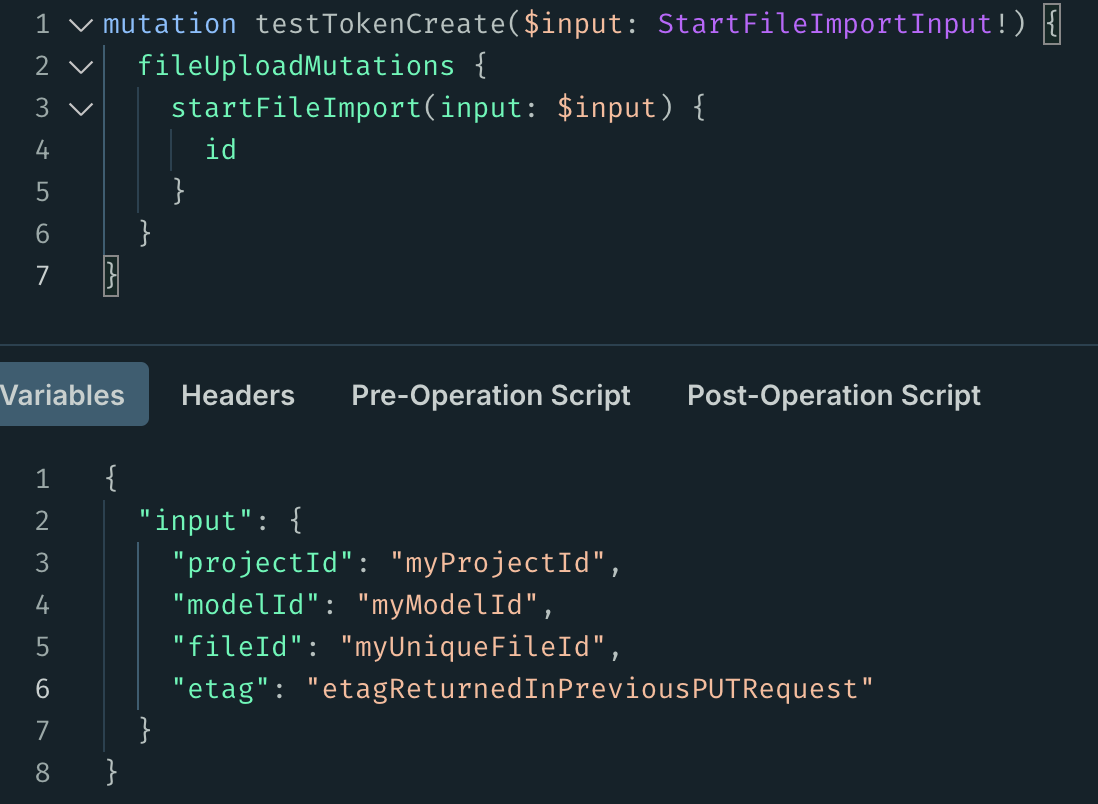
Finally, to start the process of parsing the file and importing it as a new version to a Speckle model one more graphql operation is required. Please make a POST request to /graphql with the mutation fileUploadMutations.startFileImport. This input should include the following:
projectId, the same value as used in thegenerateUploadUrlmutation before.modelId. The imported version must be assigned to an existing Speckle model.fileId. This can be any value which uniquely identifies the specific file which was uploaded. A hash of the file, or hash of pertinent metadata related to the file, or the etag would suffice.etag. This is the value returned in the previousPUTrequest.
Congratulations! The file import will now start and begin the parsing of the file and creation of the new version of the specified Speckle model.
Instructions for self-hosters
These mutations are also available to self-hosters of the open source Speckle server. For the above-described method to work it requires the S3-compatible blob storage is accessible from the same network in which your users are accessing your speckle server from, which could be the public internet or corporate intranet. This may require adjustment of firewall rules around your S3-compatible blob storage. Before making your S3-compatible blob storage accessible from an external network we recommend a security audit. In particular, publicly-accessible buckets should be disabled.
This method also requires the blob storage to support pre-signed urls which most S3-compatible blob storage solutions should support.
Thirdly, the networking architecture of speckle server may require the blob storage to have a separate url when accessed from the public internet or corporate intranet compared to when accessed from a private network in which the server resides. This is likely the case if running speckle server and the blob storage in a Docker network. In this case we have provided an additional environment variable to the server which can be used for this; S3_PUBLIC_ENDPOINT is now available alongside the existing S3_ENDPOINT.
As always please post any questions and queries below. We will try to support you through this change.