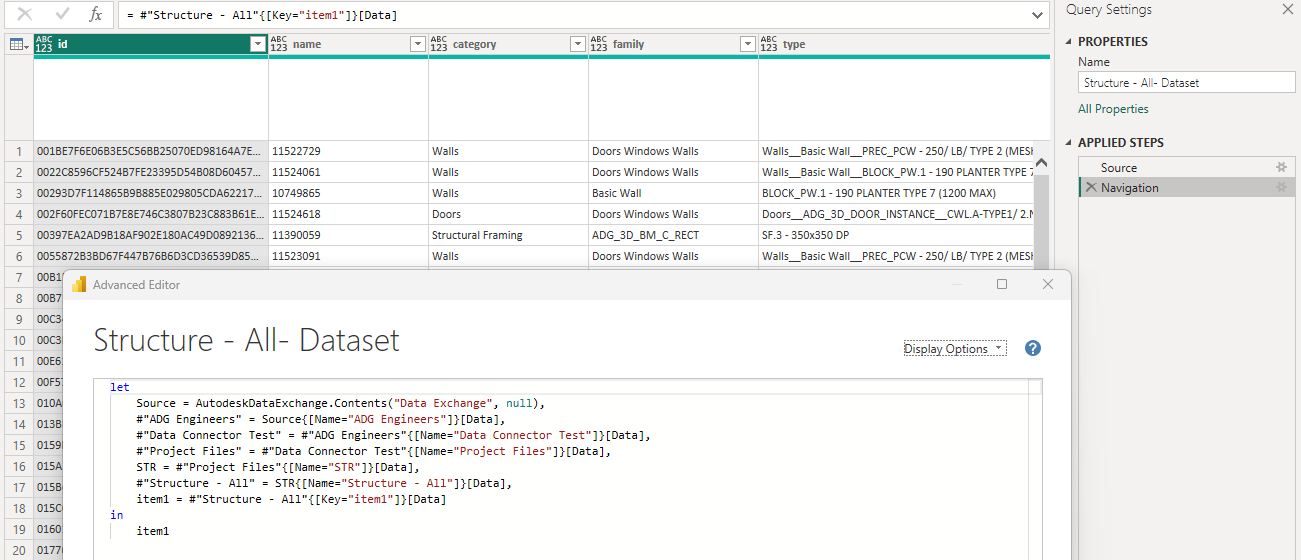
Just a bit of feedback on bringing data exchange into Power BI. Once I have identified the source, if automatically creates all the relevant columns without the need to apply addtional steps as I do with the Speckle connector. Just noting in case you can adopt a similar method.
Thanks, @BIM_Wash - indeed, the data presented by ACC to PowerBI is tabular, meaning some man-in-the-middle transformation is already being performed.
I commented on this in your LinkedIn post. A mature ETL process is always beneficial, but if you think we can do more to allow for this restructuring directly in the Speckle PowrQuery namespace for out-of-the-box queries, this is helpful feedback.
We’ll publish our Open Office demos from SpeckleCon soon. In it, we showed how to leverage Speckle GraphQL API to have the server deliver just the data you want to visualise before it even reaches PowerBI. This strongly contrasts the ACC route, which is a push to a “baked” dataset.
We also want to publish templates, or “PowerBI Apps”, which already perform some of the common transformations we see being made.
We are data source agnostic at present, but specifically for Revit I see how this is useful. We also envisaged Speckle Automate being able to have common data tasks encapsulated such that a solution exists somewhere in between raw data and the ACC result for Speckle in PowerBI.
I’d also love to hear your view on the specific model ACC employs of bake and push and its implications for performance and cost.
to have the server deliver just the data you want to visualise before it even reaches PowerBI.
yes, this will be critical to only bring in the relevant parameters. Right now, it is almost at a point where the lag in PowerBI is getting frustrating, especially when I compare the experience to Kibana in the ELK stack.
Can you identify which fields are auto-generated and suggest additional fields that may be helpful?