Just had my first play-around with the Speckle Processor and so far it works like a charm!
Now I’ve investigated some basic workflows such as filtering stream data and merging different streams (can share vids if anyone interested), but now I’m interested in doing a bit more advanced stuff.
I would like to do the following: GET data from a specific object in a stream > restructure data in the way my REST API wants to receive the data > POST & GET results from REST API (with standard Speckle processor) (with wait for 10000ms) > restructure data in the way I want to store it in my stream > store data in new stream > create a new stream.
I was wondering if this requires me to make a new lambda function, or it is possible with the current SpeckleProcessors. Maybe a quick screenshot of how to fill the REST API Result Embedder would already give me the answer.
Glad to hear you could get started with Processor so quickly, for this question I’ll ping @mishaelnuh if he has time to reply.
A word of warning though, Processor is still just a proof of concept to show what can be achieved by building on top of Speckle. It’s not meant for production and we can’t provide much support on it atm.
Any feedback is still much appreciated anyways, and it will help us tailor 2.0 development in the right direction!
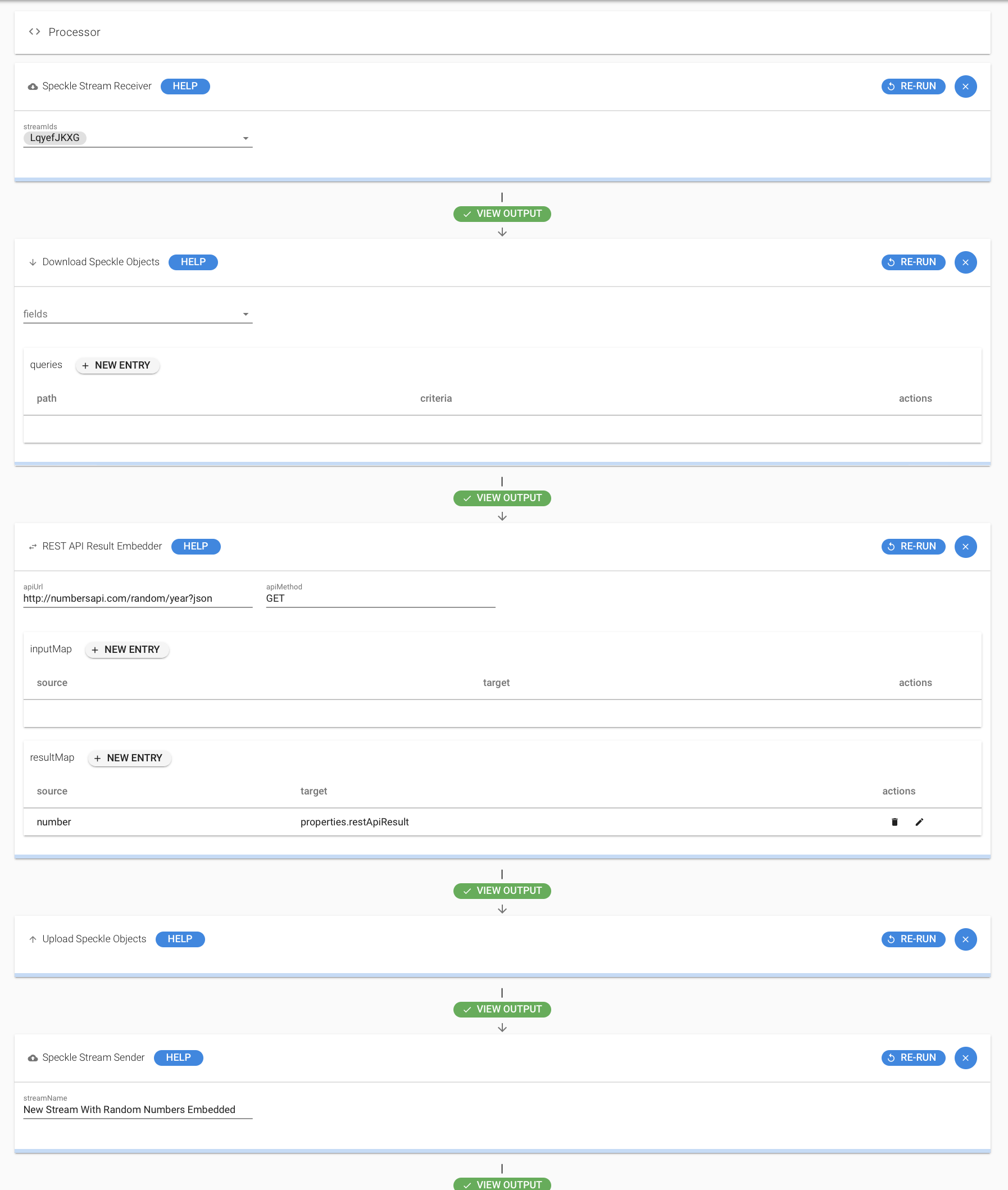
Sorry for not getting back sooner; things have been hectic. It’s been over a year since I looked at Speckle Processor and I expect things may have changed which affects it. Nevertheless here’s a simple example of how to use the REST API block. The steps takes a stream filled with blocks and calls a REST API for each item which then gets embedded in each item. It uses stream LqyefJKXG on the Hestia server. My output of it is on stream ID onBIojG1- on the Hestia server.
If you go to this link, it should import the Processor for this: here.
In case that doesn’t work, here’s a screenshot which you can use to recreate it.
Receive the object IDs of every object in the specified stream
Download the speckle objects locally for use on the REST API Result Embedder
Specify the API to call on each object. You can specify the method here as well as the endpoint. For POST methods, you should be able to pass on parameters and also format them. For example, if you have data in the field Load and want to pass that on as Force, use the inputMap with the source as Load and the target as Force. I don’t have an easy access to a POST API endpoint to test this but hopefully it still works. In the example, I used a numbers GET API endpoint which outputs a number field and I want to store that on each object in the properties.restApiResult field. Note that it uses dot notation and for the purposes of the viewer and other clients, stuffing stuff in the properties bag is a good way to go.
Upload the modified objects which returns object IDs of the modified objects.
Create a stream with all the object IDs from before.
It may be easier to actually create your own block for your REST API. All the code for the pre-existing blocks can be found here: SpeckleAdmin/src/store/lambda at master · speckleworks/SpeckleAdmin · GitHub. You can see there’s an ArupCompute block which is tailor made for a specific REST API endpoint, including authentication through Azure.
Let me know if you have any questions! Again, all this stuff is kinda blurry for me since its been a while but I’ll try my best to help. I’m also not sure what’s happening with Processor in 2.0 but it may be worth waiting/poking @teocomi or @dimitrie.
Thanks for the reply, I’ve got one more question though: are you planning to integrate the Processor in 2.0?
I really hope so as I am quite enthusiastic about this!
I think more and more companies are building their own calculation/analysis tools on the web and it would be just very helpful to do something quickly with a “simple” filter and REST API call. Getting the results back also allows you to store them in the model itself which only increases the value of it and makes it the “single source of truth”.
Of course, you could build a custom app or addition to Speckle or some sort of client, however, I think that would probably take much more effort than this simple processor workflow.
Anyways, looking forward to get your insights on this!
We’ll definitely include something like processor in 2.0 at some point, but can’t really tell you how / when / where as we haven’t really started discussing this internally .
We’ll keep you posted, in the meantime, if you’d like to share with us specific use cases and needs for such a functionality it will help us a lot getting it on the roadmap!
And yes, you can totally run those functions on your server (a part from the ArupCompute one), I’m not sure about their deployment but I think we were using Netlify Functions: Netlify Functions | Netlify
I am thinking of multiple use-cases, starting with this example:
We got a structural model with the analysis FEM results like internal forces/displacements etc. stored in a stream on Speckle. This could be a set of piles supported by a deck (jetty structure).
Now we are interested in the unity checks for the pile sections and therefore we would like to filter out the piles, extract and format the data needed for an API call to our own pile section calculation web-tool. The Speckle processor defines the filter, the structuring of the data for the API call and where to store that information after the calculation is finished.
That would be one basic workflow to automate data transfers in structural engineering workflows.
And if there is a functionality to color objects based on filters we could quickly get insight where we can optimize and where we are using the maximum capabilities.
Basically, the processor would allow us to leverage the power of Speckle for the people who don’t want or can (visually) program which would then result in a wider adoption in my company (mainly specialist/engineers)
If you need more information or potential use-cases I am happy to share.