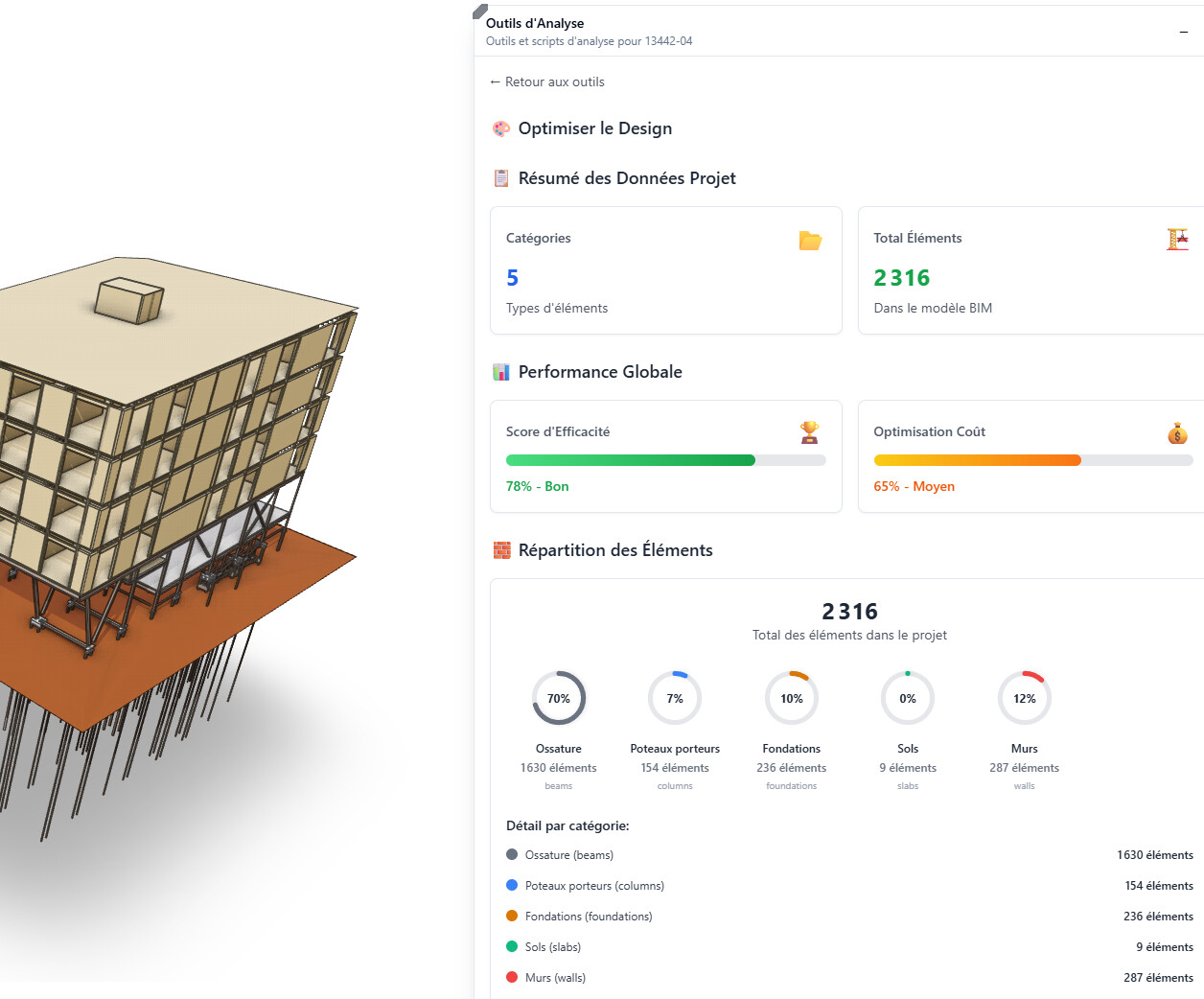
Hi everyone, ![]()
I’ve seen several posts here about LLM integration with Speckle data, which motivated me to experiment as well—so credits and thanks to everyone who has shared so far on community !! I wanted to briefly share what I’ve achieved and ask for advice on next steps.
I built a basic LLM that queries a custom “Speckle Database” (JSON/TXT files extracted daily from Speckle). Since project data changes a lot during design phases, refreshing the database is important to keep answers accurate. The quality of results depends heavily on the quality and granularity of the JSON.
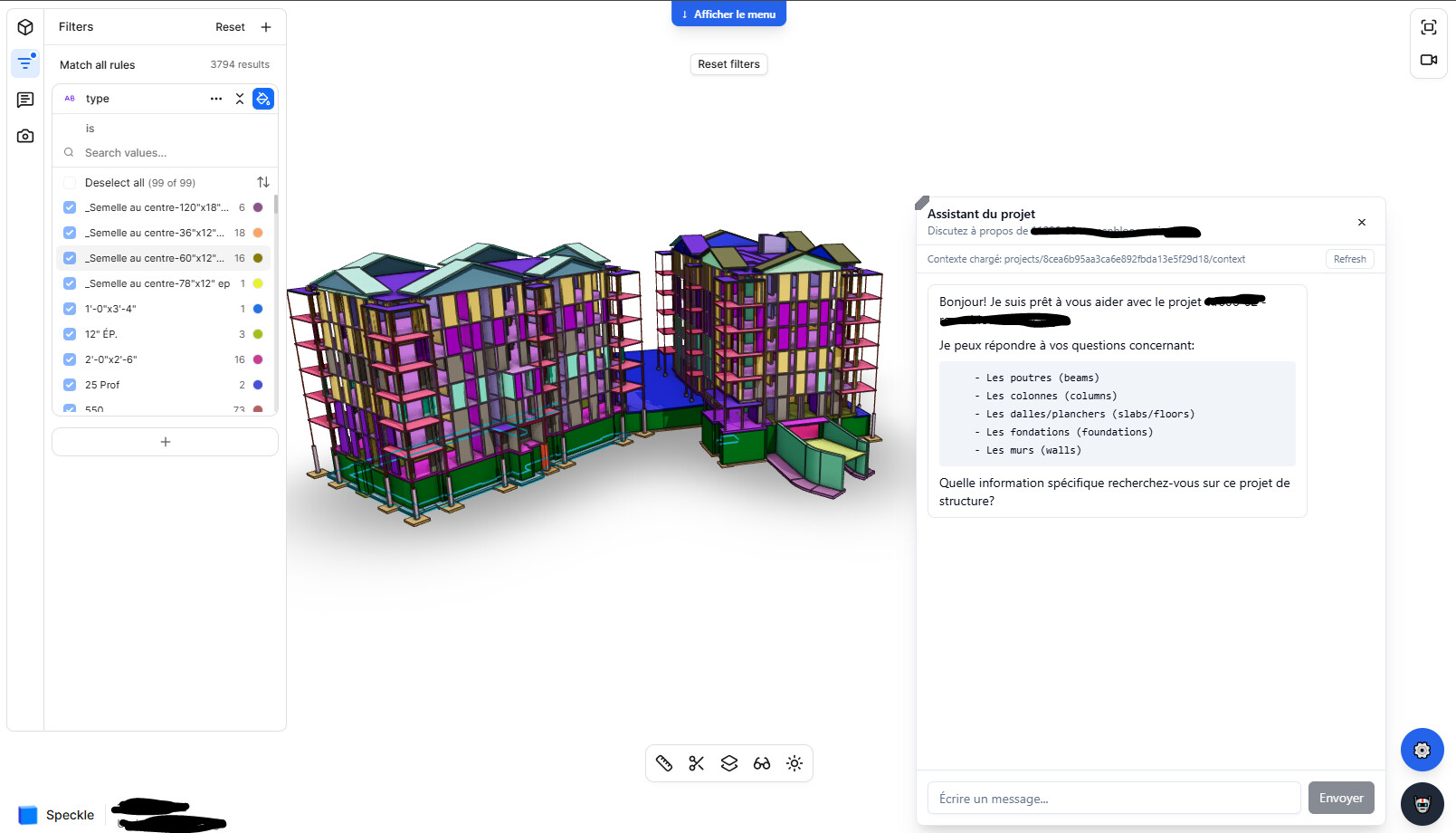
Everything started by following this Speckle YouTube tutorial, I separated data into multiple smaller JSON files. A small script detects which JSON to open based on the user prompt, so only the relevant data is passed to the LLM. This optimization dropped costs from ~$1 per prompt to ~$0.04. (Depending what model I use, still not sure wich one I prefer for this task).
Example: to get the total price of steel, only the steel material objects (with cost parameters) are loaded—no need to pass the entire model. This approach works across connectors (e.g. Revit, Etabs) with the same structure, making it fairly universal.
Right now, it works quite well, though very complex queries still hit limitations. Where I’m getting a bit lost is in the next step: I keep seeing mentions of AI agents, vector databases, n8n, PandasAI, LangChain, etc. Should I stop using GraphQL ? Has anyone here experimented with scaling their workflow using these tools—or found other approaches to take this to the next level?
Exemple I get right now : In french
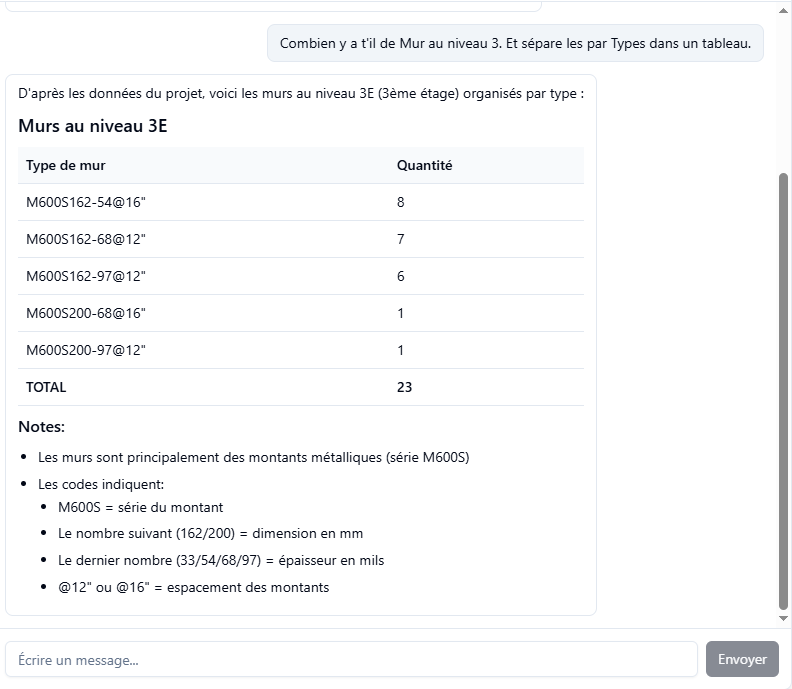
Since I’m doing all of this on the official Speckle server (not a self-hosted build), should I expect any limitations in terms of scalability, API usage, or access down the line?
We are considering deploying this tool internally with a Speckle Business license, and I would like to confirm whether this is the right choice.
Any recommendations or experiences would be greatly appreciated!
Thanks,
Gabriel S.