Looking to start a project in the new year and our modellers want to use speckle for data management.
We’ve had issues in the past where our computational designers have become a bottleneck on projects, so I’d like to set up a system where, if possible, our grasshopper scripts are run automatically whenever the modellers push updates from Rhino - current thought is:
Modellers model
Modellers push to speckle branch A
Our server listens for the push
A rhino compute instance runs, pulling the changes from branch A, doing work, and pushing to branch B
Modellers get a email when work is ready
Most of that is straightforward, just giving you the full context. The main question I have at the moment, whats the best way to set up speckle to get this to work? Is this even an intended use case for speckle?
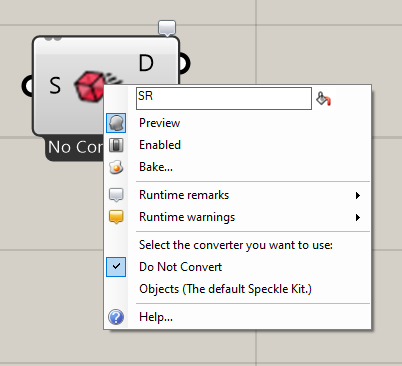
One immediate issue I’ve had is that the Synchronous Reciever node is throwing exceptions when it is called within a rhino compute instance:
An exception occurred while processing request
System.NullReferenceException: Object reference not set to an instance of an object.
at Objects.Converter.RhinoGh.ConverterRhinoGh.SetContextDocument(Object doc)
at ConnectorGrasshopper.Objects.SelectKitTaskCapableComponentBase`1.BeforeSolveInstance() in C:\Users\circleci\project\ConnectorGrasshopper\ConnectorGrasshopper\Objects\SelectKitTaskCapableComponentBase.cs:line 142
at Grasshopper.Kernel.GH_Component.ComputeData()
This seems to be a reference to RhinoDoc.ActiveDoc which has been identifed as an issue in converters: Pull 749.
That being said I don’t want to dive into bugfixing if this isn’t the right direction more generally…
Interested to hear if anyone has been down in this road before and give me some pointers about where I should get started.
This is definitely a scenario we want to support via Speckle. Our long term vision on this would look a bit like GitHub Actions, see this thread by @messismore : Speckle Actions! Suggestions?
Currently, I think what you describe could be, at least in part, possible via Rhino Compute, but I’m not too experienced with it, so I’ll ping some folks who might be able to help you some more: @Stam who created the Synchronous Reciever for use in RC and @vwb who I believe fixed the issue you have with the ActiveDoc (maybe you have an update pending?).
Cheers Matteo, yes I’d love to get input from people familiar with the codebase - I branched it and started making a mess but got about an hour in and decided I was just creating more problems (as I shift in my day-to-day from programming to management this is happening to me more and more ).
I got stuck just 1 step ahead as you @chris.welch. My PR fixed the issue specifically on the Converters, but there are more places where the components are assuming there will be an ActiveDoc (e.g. the SyncReceiver).
I believe if you choose “do not convert” you will walk one step further. The thing is now you will need to convert things manually, that’s very possible and there are examples on the forum (Speckle nodes and Hops - #7 by vwb).
What is not possible, yet, is to disable the conversion on the SyncSender. Meaning you will stumble on the same exception if your workflow needs to send anything back to Speckle.
I had to drop working with this for a while, but intend to come back and contribute if more people are interested.
You’re right though that we can’t actually write anything back to speckle without specifying a converter and speckle trying to ping the rhino doc and crashing. It’d be great to be able to fix as this would unlock so much potential in the short term - I’d like to hear @Stam’s thoughts on how the nodes are working currently…
So that affects the coverters and the connector itself, looks like there’s references to RhinoDoc.ActiveDoc all through the codebase. Based on the warning at the top of the API docs ( RhinoDoc.ActiveDoc Property (rhino3d.com)) you’ll also see this causing issues on Mac in the future.
Bummer! Thanks for finding this Chris, since we use the ActiveDoc mostly to get the document units I think we could provide some sort of fallback method. Or maybe there’s a better way to get units inside of a Compute environment?
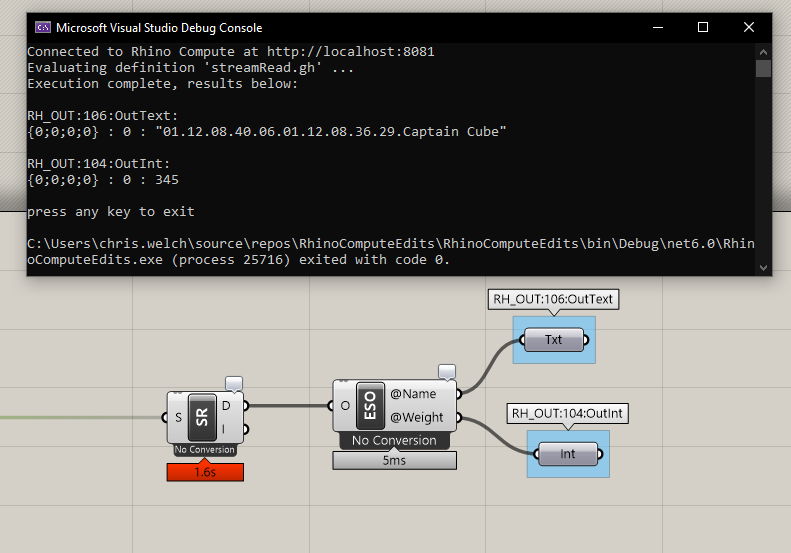
The only thing you need to ensure is that there is at least one annotated RH_OUT group to send data back to you or the server will throw an error (I just chucked the speckle commit message in there, as in this case we’re obviously just sending the work elsewhere)
Compute has no Rhino Document, so it is unitless, which also means it has no tolerances, meshing parameters, path, document path, etc. I made a wrapper for some of this information with some baked in defaults, but its all hard coded. Additionally theres some other areas where things like hatches, materials and blocks will either need to not import or require a parallel system for managing that kind of geometry outside of Rhino.
This is enough of a proof of concept for us to move forward with our plans, so I’ll revisit this in a few months - if anyone else wants to have a go at this in the meantime, please be my guest!
thanks for this!! I had a look at your code changes and I must confess I also played around with that idea, but it has some drawbacks that I think we could overcome in a different way.
Hey @AlanRynne, read over your notes and that all sounds like the correct way to go - ensuring there is always a doc, rather than throwing in a bunch of edge cases if there isn’t, is a much more elegant solution to that problem.
The only thing I can think of as a wrinkle is ensuring you could set up different templates for different streams, but that is probably an environment thing that could be managed in any number of ways on the compute server, outside of speckle.
Glad I can help, please keep me in the loop if theres any testing that can be done!
I think I added it somewhere in the list, but it may have also been a bit cryptic.
Since this is all theoretical at this point, our initial idea for this “wrinkle” was to check that this could be automated or semi-automated with a short script in your GH/Rhino file.
Still not sure about the specifics on this though. In GH, you could have a script overwrite the default template or straight up modify the “global doc” we are creating by loading a provided one instead.
In a more pure Rhino.Compute setting (with no Grasshopper), I’m not sure yet, but would welcome more feedback/suggestions on this as we go along.
As you say, there’s many ways to handle this outside of Speckle, as long as we provide enough flexibility on our side of things.
@AlanRynne just wanted to touch base on this item as we are running into these limitations using Speckle in compute as well. Was hoping something changed in the last 6 or so months, but during my testing today it seems like that is not the case. Any updates would be much appreciated!
@zb_anderson if you want to experiment and are comfortable working with a very hacky band aid, the fork I linked above does work and my team and I successfully ran a workshop with it with a little bit of manual configuration.
Here is some code I use to receive data from Speckle using Rhino Compute, just dump this inside of a C# script component in GH. This will get you the latest commit on specific branch. If you need a specific commit you need to customize it.
using Speckle.Core.Api;
using Speckle.Core.Credentials;
using Speckle.Core.Transports;
[...]
private void RunScript(string streamId, string branchId, ref object D)
{
var account = new Account();
var token = "access token that you get at https://speckle.xyz/profile";
var serverUrl = "http://speckle.xyz/";
account.token = token;
account.serverInfo = new ServerInfo
{
url = serverUrl
};
var client = new Client(account);
var stream = client.StreamGet(streamId).Result;
var branch = client.BranchGet(streamId, branchId, 1).Result;
var objectId = branch.commits.items[0].referencedObject;
var transport = new ServerTransport(account, streamId, 120);
var data = Operations.Receive(objectId, transport, null, null, null, null, true).Result;
D = data;
}
@AlanRynne - Has there been any further thought or progress on this?
We previously had Speckle v1 workng on RhinoCompute thanks to @Stam additions (sync sender) and now we’re looking at what is necessary to get Speckle v2 running on RhinoCompute (account manager, sync operations, headless docs), and hopefully avoid the scenarios o needing to put c# scripts into the GH script.
After reading your Notion page, one thought that occured to me is that if Speckle creates the headless doc, that precludes the script doing that before hand for any other plugins that might need a new headless doc (e.g. Elefront). Otherwise we could end up in a situation where the GH script author creates a headless doc, and then Speckle creates another one…
As of 2.10 release, we lifted the limitation on our grasshopper components that prevented them from working due to the use of ActiveDoc and the expectation that it would not be null (incorrect expectation, that is)
This is still being experimented with, and we’d love any feedback on this while we’re still shaping it up.
The way it works right now, is that our Grasshopper components will detect if Grasshopper is running on Headless Mode and if so, we’ll create a new headless document that will be shared for the entire solution.
This ensures that the document is created before any component tries to use it, and that it will be disposed of after each run.
Then all components call GetCurrentDocument which determines what to return.
There is one limitation on this right now that we’re working on removing:
We will currently create a headless document with no extra inputs, meaning that (as far as I’m aware) the headless document will be created with Rhino’s default settings.
We’re aware this may not work for everyone, so we’ll be adding an option to override this in the near future. Boilerplate for this is already in place, but we’re trying to work around some final issues before exposing it.
Exceptions
Only exception to this is, logically, both our Send and Receive nodes, as they inherit from GH_AsyncComponent that is not rhino compute capable. But the Send Sync and Receive Sync are there to save the day.
@AlanRynne - Thanks for those code snippets.
If I’m reading those and the GH Dev docs correctly, then currently the Speckle addin will create a new Headless doc, irrespective of whether the Speckle components are used in the current GH_Document .
(i.e. You’ve hooked the SolutionStart/SolutionEnd for all documents added to the GH_DocumentServer, not just the ones with a Spceckle component in the script)
Is that your understanding?
I’m not sure whether its right or wrong, however, as you’ve noted it takes some control away from the script author being able to define the template/units.
And it does mean GH Script authors need to be aware that sincle Speckle plugin is loaded, they shouldn’t create a headless Doc in the script, since you’re keeping a private reference _headlessDoc. If the script author subsequently creates one in the GH script, then I suspect the Speckle components will get the wrong headless doc?
True, but only when Grasshopper is running headless. As far as I’ve been able to tell (I may be wrong here), each run on Rhino.Compute will have it’s own “Rhino/Grasshopper instance”, so even though it seems the events are over eagerly added; they actually only get called once. @luisfraguada may contradict me if needed We tested this with Hops and seemed to be consistent.
I’ll confess I’m no expert on the inner details of Compute so there may be some edge cases left.
Correct, ideally this would be done as some sort of global setting that could be stored in the document itself (not sure exactly how yet). This could allow the user to set some path in the GH document (or even pass it as an input to compute). We’re still looking into this.
I fear that the prior fix of “adding your own HeadlessDoc as the ActiveDoc” was not something very user-friendly. It is also difficult to guarantee the execution order in Grasshopper, opening the door to a Speckle node running before the document was readily available.
But yes, authors should be aware of this. I wouldn’t consider it a “Breaking Change” as our nodes didn’t really run on Compute without the aforementioned hack, but definitely something to be aware of
What other scenarios could you think of where a user would have the need for a Rhino.HeadlessDocument inside a Grasshopper headless run (other than Speckle itself…)?
If the only reason a user would set a headless doc is to have Speckle working in Compute, then I’d argue that there would be no chance of ending up with the “wrong” headless doc, once we add the option to specify which template to use.
We’ve been running Rhino.Compute instances for over 12 months, and have found other scenarios such as using other plugins which rely on the ActiveDoc (e.g. EleFront) or where the script is going to import some geometry (from a 3dm) or export/bake some geometry to 3dm/DWG. (Sadly, not everything is Speckle based yet )
So far we’ve handled that by making sure the headless doc is setup by a small script node at the start of the GH script, and anything else downstream is chained from that. Sure, it’s possibly not the most user friendly, but it generally works and means the script can run on desktop or in headless mode.
Thanks for reminding my the sync sender/receiver are still there. I think we’ve also had some issues with components such as Get/List Stream as they (currently) have no sync equivalent.
 Speckle Actions! Suggestions?
Speckle Actions! Suggestions? ).
).