Hey @iltabe, we like long texts - thanks for your insights; this is really helpful for us. I’ll try and reply - hopefully coherent!
You have that level of granularity; what happens though, given the fact that objects are immutable in speckle, is that your new object gets a new id (hash); and so does his parent, and the parent’s parent if any. The object’s applicationId though stays the same, and this is how we actually manage to “edit” existing elements in a revit file, if the revit api allows, of course.
Ultimately changing element properties is easy - the main limitation is the integration with the host software when bringing those changes in (hint: it’s all very limited!).
Diffing is again is a difficult subject to breach, but actually thinking things through based on what you said, it can be done nicely 
The brute force approach would be to diff against the whole commit structure - ie, across potentially 100k+ objects. This can be done, but it’s not sustainable and I believe quite meaningless.
The brainwave which I got after you described your case is that we can actually do it on objects with applicationIds only. This is super cool, because:
- you’d be able to see, side by side, how a given object has changed!
- it would also give you a more concise classic diff (added/removed/common), though this could be done also based on speckle ids (hashes) too.
Not using git, but I’ve been heavily inspired. Speckle doesn’t have a demarcation between a tree and blob, like git, but each object is simultaneously a tree (of references) and a blob. This is because git has a nice tree structure to operate from from the start - your project’s folder structure; whereas Speckle needs to work with however the authoring software keeps data structured.
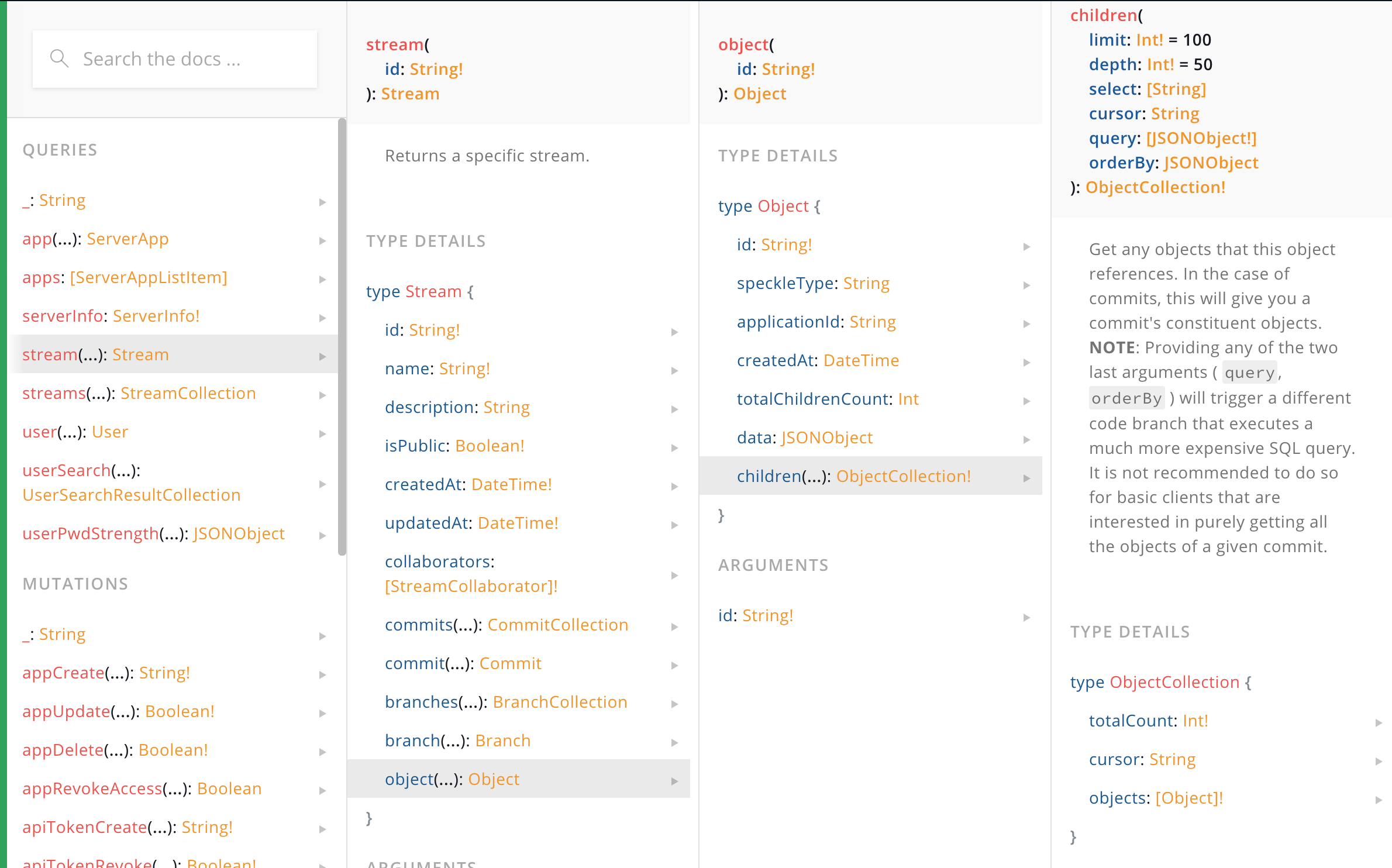
But don’t worry, you can query a given commit in a classic way - ie, “give me all the objetcts of this type with this property bigger than X”. It’s the query param for the objects type in case you have a server around to play with:
This is documented in the tests only at the moment: speckle-server/modules/core/tests/objects.spec.js at 692c0b02827e31023f1c4ab027e0ef6373802ece · specklesystems/speckle-server · GitHub