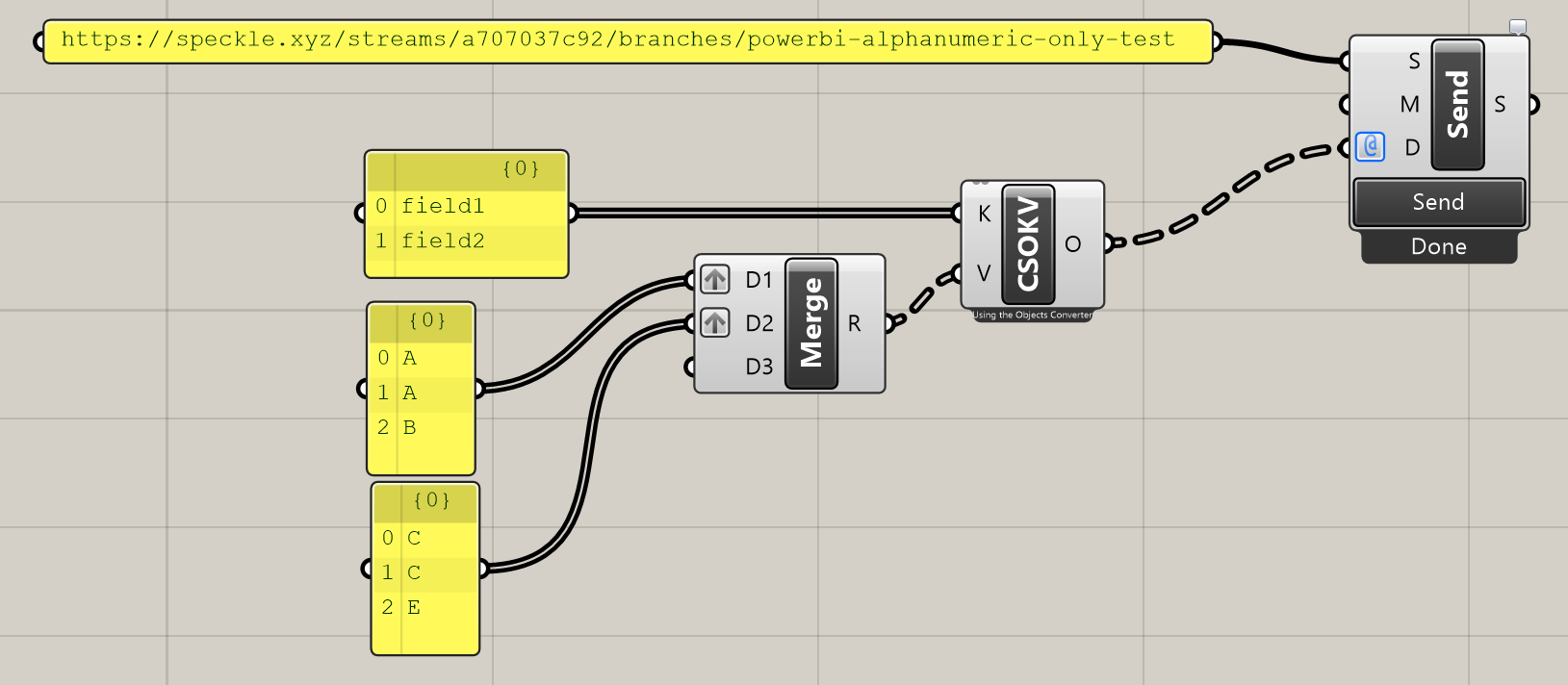
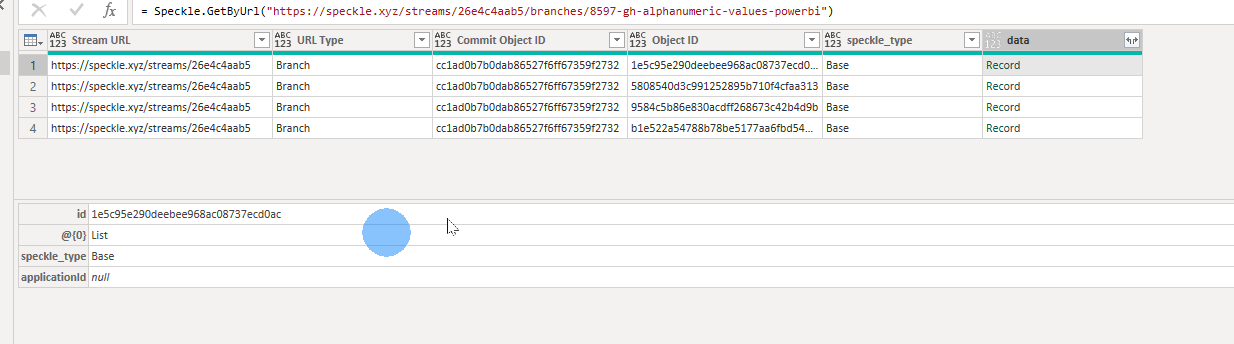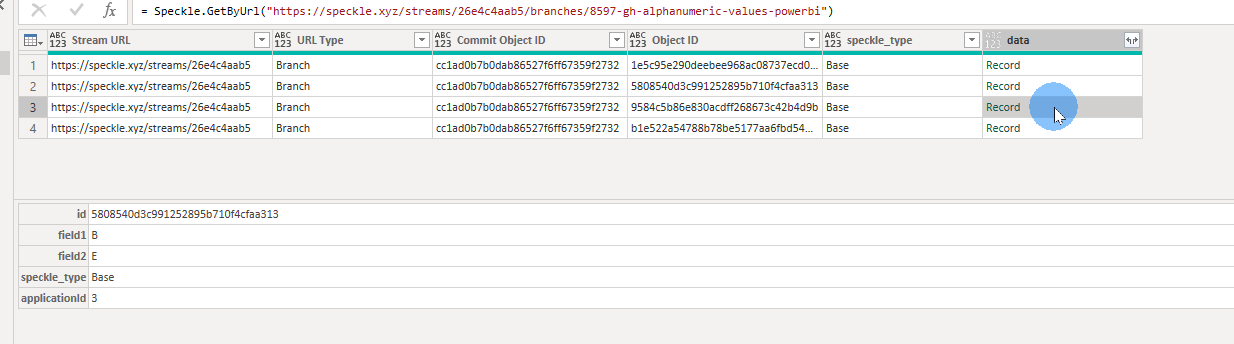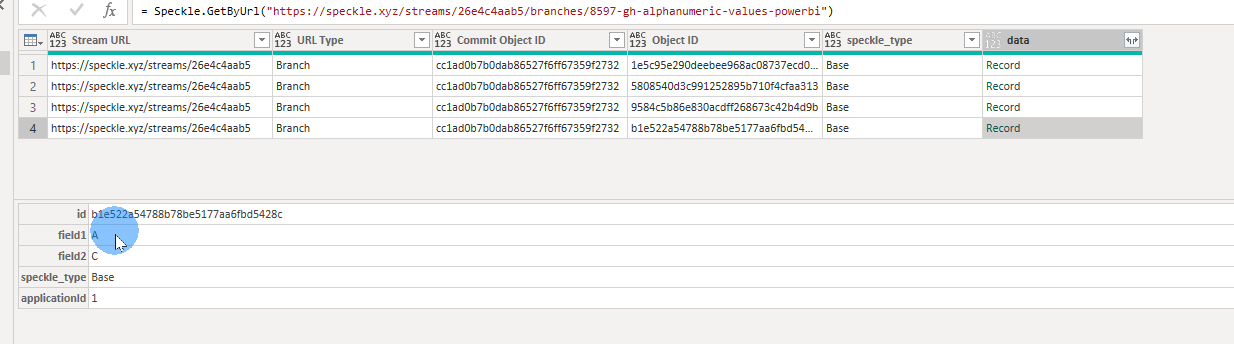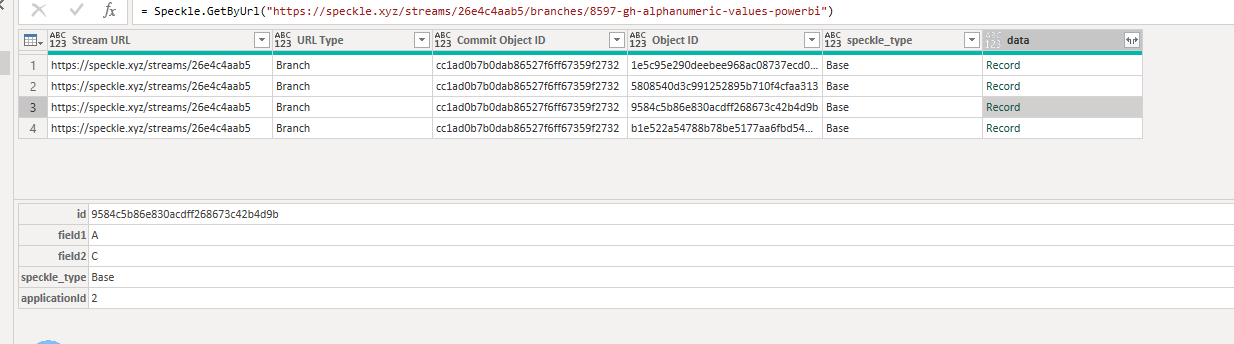
When uploading some alphanumeric-only data (no geometry), I noticed that for two or more rows that have the same exact data, it shows only one row. Example below: there are two rows with “A” and “C”, but in the data from the website (second screenshot), there is only one row with “A” and “C”. Is there a way I can get it to not do that?
(By the way… I doubt this has anything to do with my issue, but I couldn’t get the alphanumeric-only upload to work with the CSO component, but I did get it to work with CSOKV.)
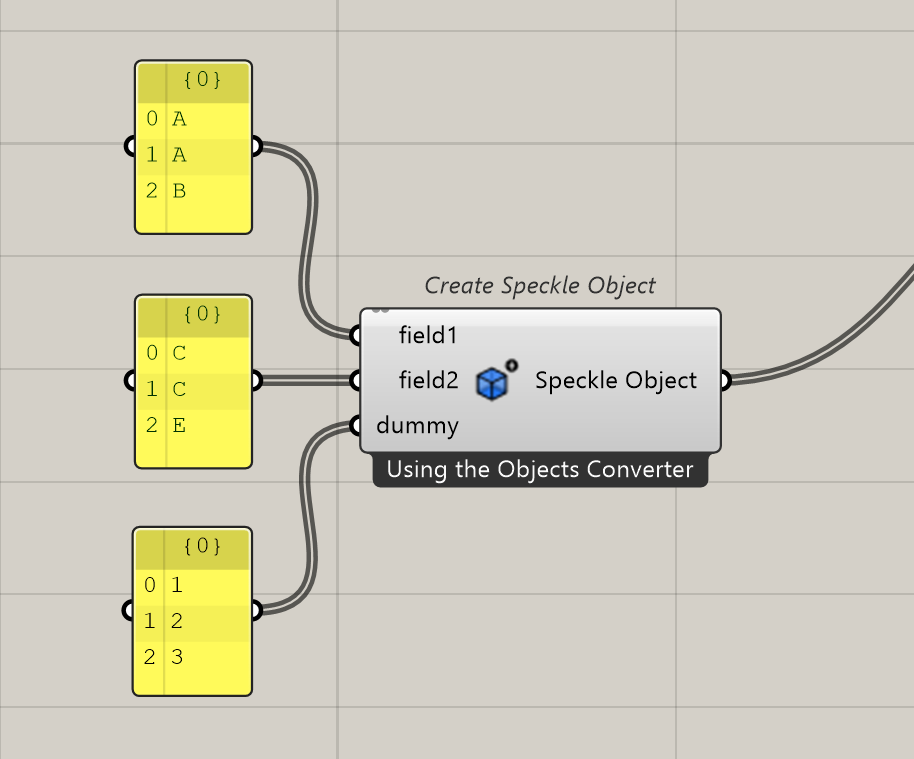
First, Let me explain the process that happens when you send an element to Speckle. We convert the object into a Speckle object and assign it an ID based on the inputs you specified. If two objects have the same input parameters and values, they will share the same ID. When this happens, only one row is generated in Power BI. To solve this problem, you can add an additional input and assign a unique value to each item. In the example shown in the picture below, I added a dummy input and assigned a number to each item. This ensures that each element has a unique ID, which can be correctly received in Power BI.
Please let me know if this solution works for you.
I completely understand what you are saying, and I understand the workaround you’re suggesting. I’m sure I can implement the workaround if I need to. So thank you.
For a future update, I would strongly suggest adding the option to not remove duplicates. While the automatic removal of duplicates is sometimes exactly what is needed, I would suggest making that an “opt-in” feature. Generally, you’d want to see that the number of items coming out of Speckle is equal to the number going in. In my opinion, this should be the default behavior, no workaround required.
If there is a different place where we should post feature change requests, let me know and I will post this request there. Overall, Speckle is a fantastic tool … thank you!
Thank you for sharing your thoughts. I totally understand where you’re coming from and agree with you. The way we structured our data has resulted in some unexpected side effects. But we will try to find a way to fix this issue without sacrificing performance. As soon as we have an update, I’ll be sure to let you know. Thanks again for your feedback, it’s much appreciated!
If there is concern about subsequent versions of Speckle seeming slower, then I would say … you can still make removing duplicates an option, but have it turned on by default. (Like “Remove duplicates” is a right-click option on the Grasshopper component that is checked by default.)
Beyond that, hopefully people will understand that if you’re sending more records through the internet than you were before, of course it’s going to take longer. I imagine the difference would only be noticeable in medium-to-large models, though.
Unfortunately, we haven’t fixed this papercut just yet. In the meantime, there is a solution that you can easily implement on the Grasshopper side, which I mentioned in my previous post. Let me know if you have any other questions or concerns!