Hey there @JdB,
yep, this has been brought up before, including the ability to “internalise” base objects.
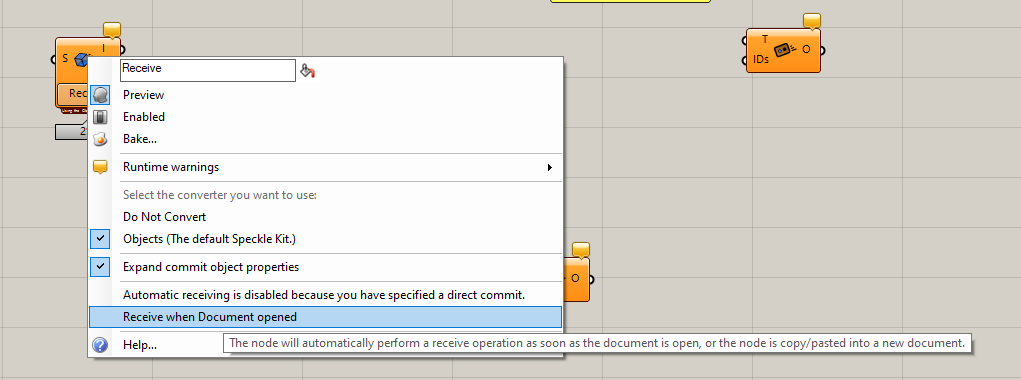
Just tell the receiver to receive on open
You’d still have to wait, but you won’t have to think about it 
Internalising data in our own Base object parameters
The problem we see here, and the reason we haven’t implemented this, is that internalising heavy objects takes a toll on grasshopper’s auto-save performance, which will be directly attributed to us (happened last week  ) when it’s not really something we can fix (or want to encourage really).
) when it’s not really something we can fix (or want to encourage really).
Doing our own caching
We already do this. Every object that you receive is saved on your local DB to prevent having to pull them from the server twice. The thing is that, in order to “save” that data in some other file, we’d have to serialise it and deserialise it (which the receiver also has to do) and also check for possible conversions. So you end up with the exact same process the receiver already does, with not much speed increase (or none at all).
Caching the objects “post conversion” would be equivalent to the first option of internalising the data, which again has the same serialise/deserialise issues when dealing with big data sets; with the added headache of having to figure out if the serialised object is Base or comes from Rhino.
Other possibility
You could already do this combining the normal receive node with a send to transport and receive to transport, where you specify a DiskTransport with the location of your data.
If the file exists, it will be read as soon as the GH file opens, but the way I see it, this will only remove the step of “pressing the Receive button”, as you’d still have to wait for deserialisation and conversion to happen.
P.S. I could be talked into implementing internalise data for base objects in a way that does not bloat the GH definition (maybe just storing the ID’s and pulling them from the DB when necessary), and that may allow us to rely on GH existing internalisation to pull this off… but I’m weary of the consequences, as “auto-save” is on by default… any commit bigger than 2-3mb will already start to slow down your GH definition to an unusable level.
For the same reason you need to run your Kangaroo scripts, Karamba optimizations or Ladybug analysis… Grasshopper just works like that, for better or worse