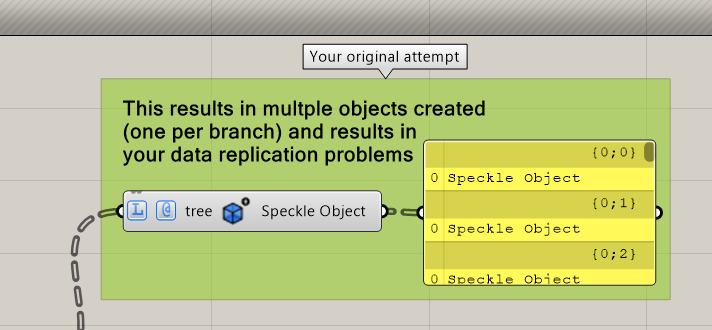
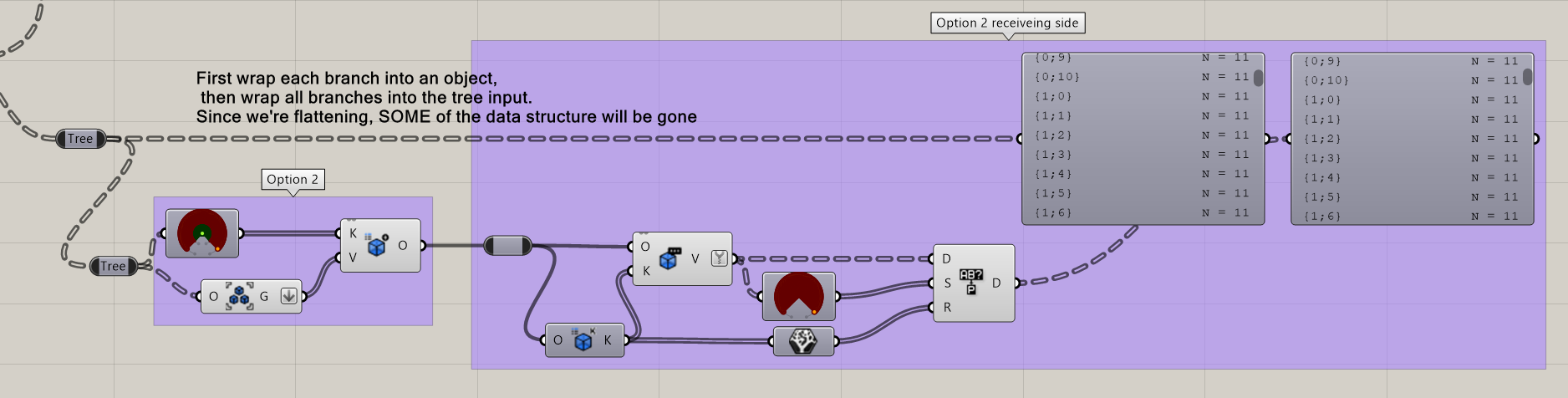
I wanted to post here first to make sure I was using these GH modules as expected before opening an issue on Github. We are evaluating the use of speckle for our GH workflows now that it is supported via Rhino Compute (this was an exciting update for us). But I have run into an issue when sending data that includes data that is a single item or list along with data that is wrapped in trees. Our workflow requires the use of trees so we don’t have an option to get rid of them as a work around.
The problem I am running into though is that the Sender, Sync Sender, and Speckle Object blocks seem to behave differently when building a speckle object. I can send a mixed set of data (single objects and a tree for example) via the inputs on the Sender block and I can get back data that is the same format that I sent it in. But I cannot use this block in compute, even with the auto-sending on, since it the compute instance closes the operation before the Sender module can execute its commit because it is non-blocking.
That means I need to use the Sync Sender but if I send this data either via directly piping the data into the data input (D) on the Sync Sender or by building a speckle object before I pass the data into the Sync Sender I get really weird output data structures that seem to nest even single object multiple times in trees. I have tried every combo I can think of to build the speckle object to try and retain the right structure (separate speckle objects, list vs no list input, detached, vs not detached, object groups, etc) but I still end up with garbage output that is multiple tree layers deep with repeated inputs which results in ballooning file sizes of some commits with heavy meshes being repeated hundreds of times.
To summarize, it looks like the regular Sender module has access to trees in GH but neither the speckle object or Sync Sender block have the same level of access. Below is an image of an example setup along with the GH file if that helps with debugging. I am also running Rhino 7 and speckle 2.14.
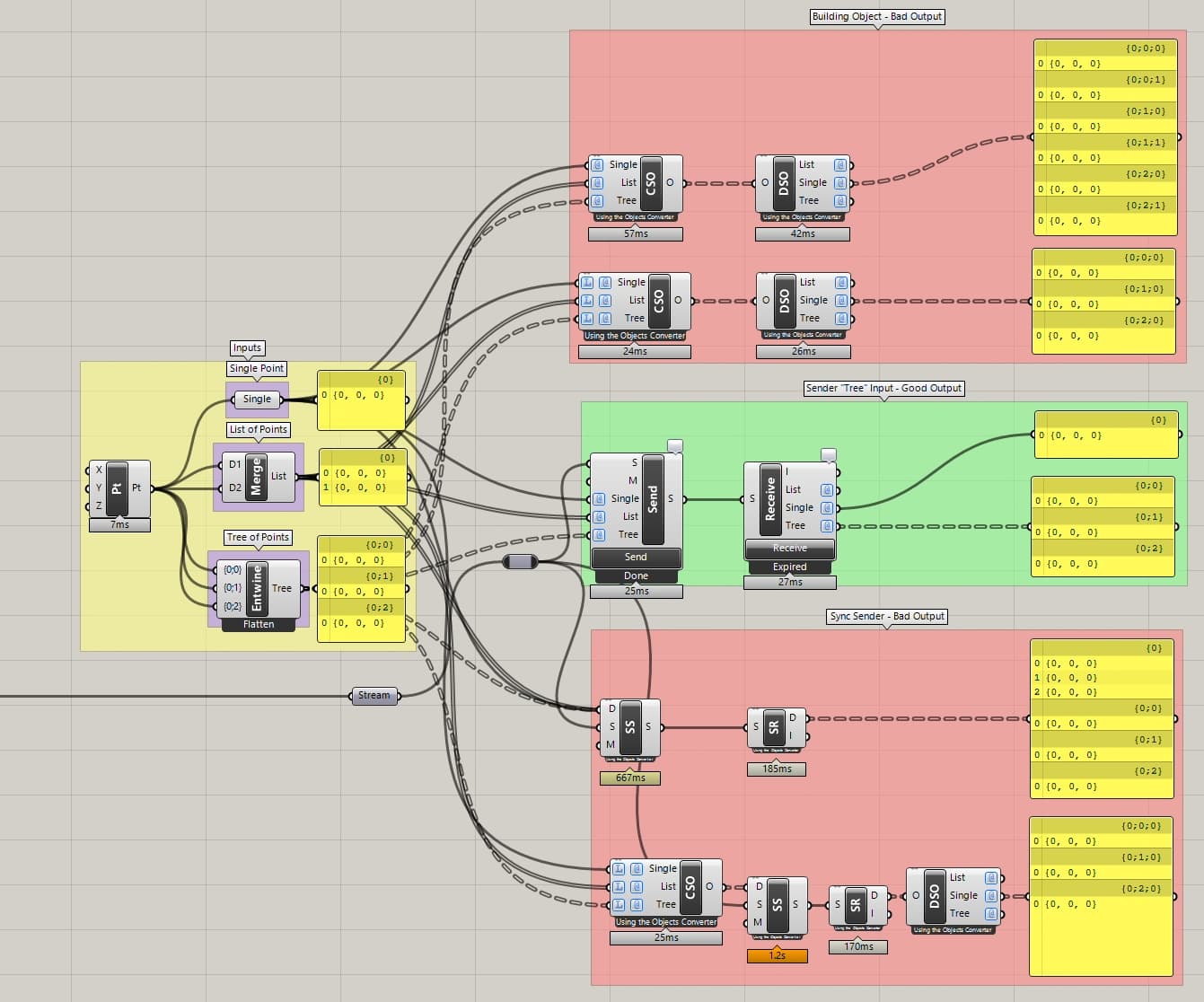
SpeckleDebug.gh (19.0 KB)
What I am looking for is clarification that I am going about testing these other object packaging methods for the Sync Sender correctly, and if I am then I can go and open an issue on Github because this difference between these approaches is hamstringing our implementation of speckle. If I am using them incorrectly (I hope that I am ![]() ) then please let me know and I will try a different approach ASAP.
) then please let me know and I will try a different approach ASAP.