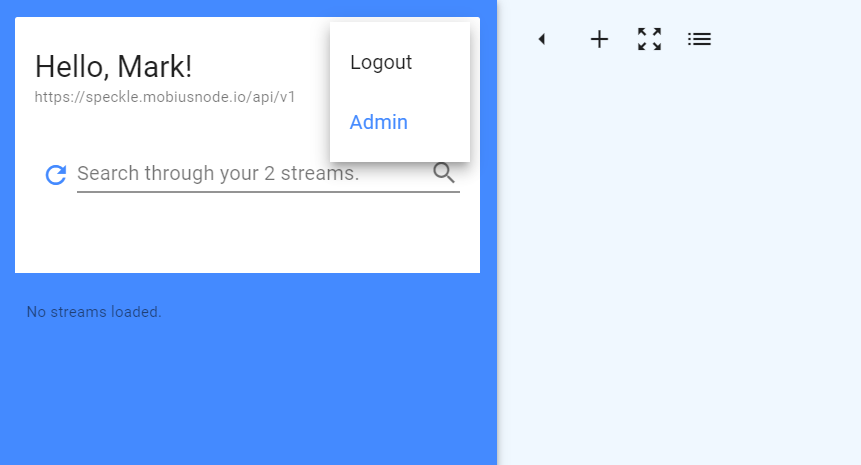
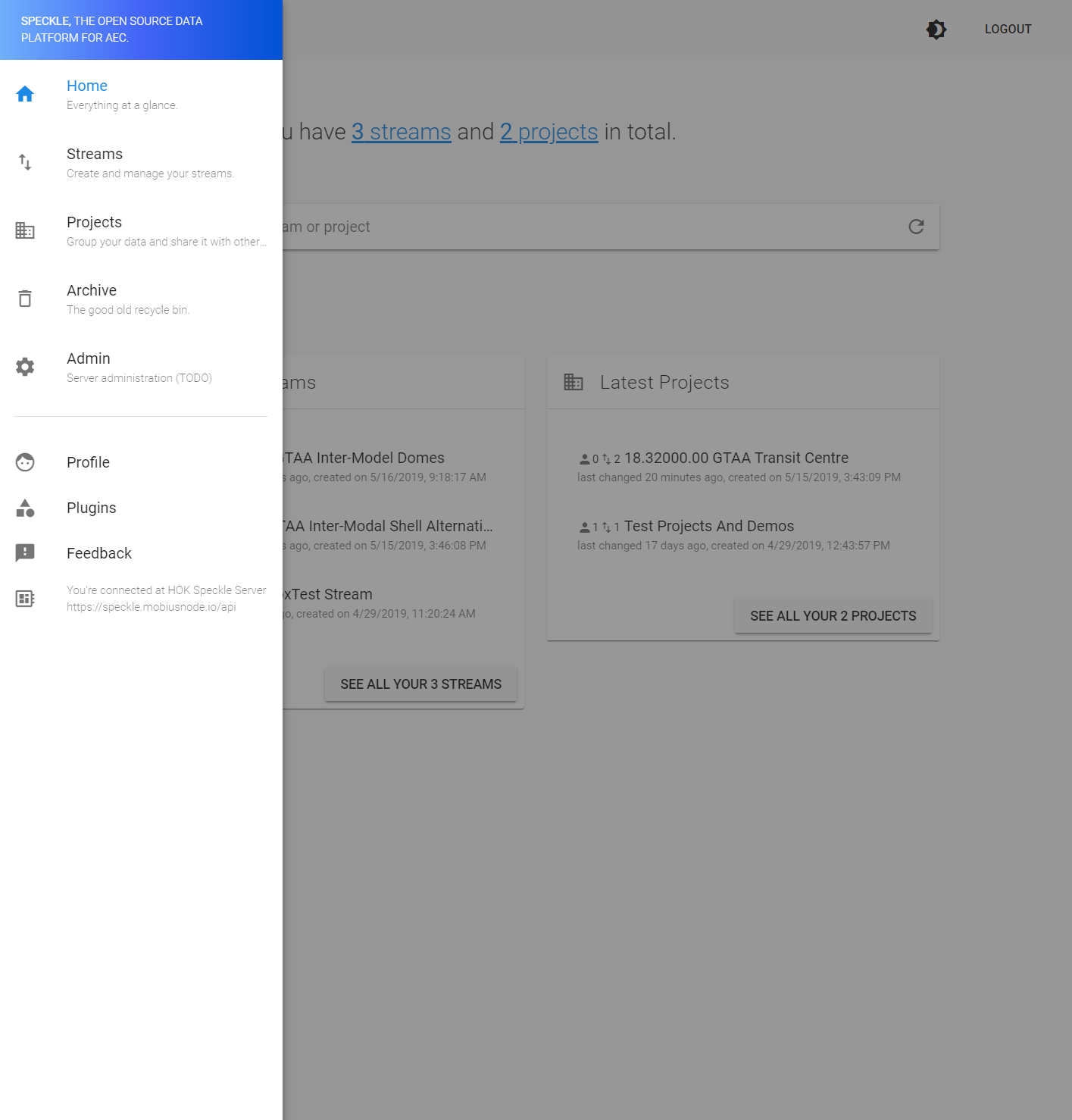
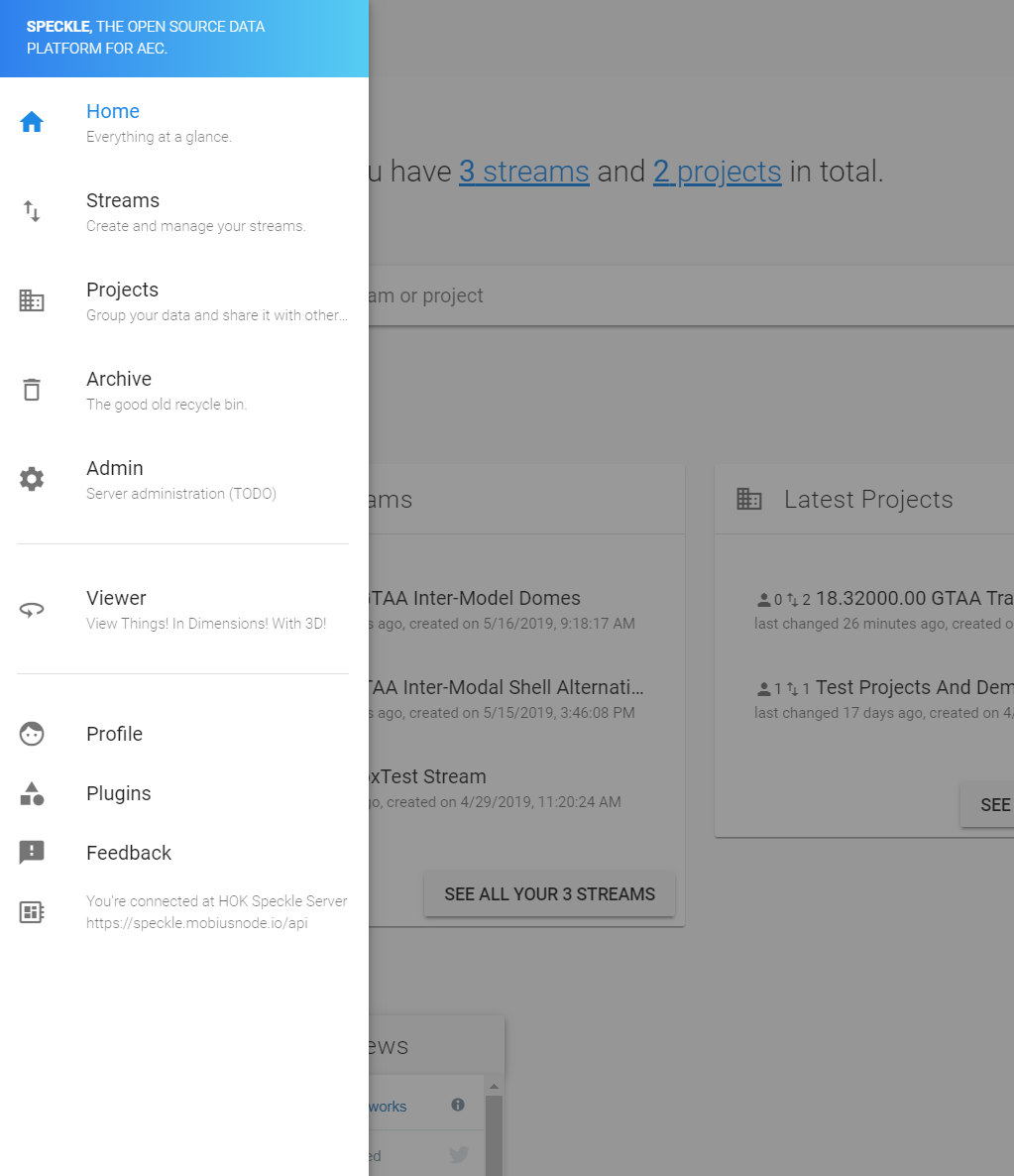
Getting “Cannot GET /admin” when switching from Viewer back to “admin.”
I think this is a simple fix: ie repoint back to root seeing as this is where Admin has been moved to in current version.
Hoping this is as easy to fix as it appears.
Getting “Cannot GET /admin” when switching from Viewer back to “admin.”
I think this is a simple fix: ie repoint back to root seeing as this is where Admin has been moved to in current version.
Hoping this is as easy to fix as it appears.
Hey Mark, this project has been deprecated; the speckle viewer has been moved into speckle admin itself, under the view tab:
If you’ve deployed the server yourself, you’ll probably want to do a git pull in the admin repo from the server plugins folder.
Fix for this? DEL cloned VIEW git repo in plugins? Re-clone ADMIN?
yep. remove the old viewer from the server plugins folder, and do a git pull in admin (if cloned previously, otherwise clone it again). note, the admin is served by default from the server’s root url.
if previously accessed in the browser, you might need to do a hard refresh to see the new version.
“Hard refresh?” Please explain. Do you mean clear Chrome cache?
did you fetch the remote first? i usually do:
git fetch to make sure the remote is syncedgit pull to pull the latest changesthat should get you going.
SOLUTION (WORKED FOR ME):
All good.
+1 as new viewer seems to come with perf bump! Kudos to employing XYZ at origin!
yes, it’s something like 1/5th of the old one’s memory usage; but there’s still quite a bit of broken things, so take care.
So, one item off the bat: when model is loaded into memory (massive GPU utilization spike, btw), objects start to load 1 by 1, but when stream is refreshed, interface breaks. Not sure how to describe this.
Model still loads, refresh warning appears, if user tries to click on any other element of UX, nothing happens. Viewer simply refreshes current state.
However, if user refreshes browser window – memory is cleared, can then use as normal.
Obviously a pain for very large models that cannot be split.
yeah, sounds like a big model there  there’s room for optimisations but i don’t have time at the moment; so my only suggestion is to split the model in more streams if possible… things in the range of 15k meshes are still responsive-ish on my computer.
there’s room for optimisations but i don’t have time at the moment; so my only suggestion is to split the model in more streams if possible… things in the range of 15k meshes are still responsive-ish on my computer.
Last question: is perf related to client machine spec?
Example, I am testing on two different machine specs:
(1) 2018/9 Macbook Pro, Core i9, 32GB RAM, 4TB SSD, ATI Vega 20, and
(2) HP Z Workstation with 8 Core Xeon, 128GB RAM, 4TB SSD, Quadro RTX 5000
Not much difference between these. On Speckle. Massive difference in Revit, Rhino, etc.