Here I am again with two additional issues / topics to discuss regarding the specklepy client:
- Creating Speckle classes during runtime using
pydantic.create_model() - Inefficient serialization due to repeated traversal of the same objects
Creating Speckle classes during runtime
In our company we create some Speckle classes during runtime. These basically mimic the classes we setup ourselves, but then of course as a subclass of Base, so they can be serialized and sent to Speckle. To that purpose, we use pydantic.create_model(), see a basic example below:
import pydantic
from specklepy.api.client import SpeckleClient
from specklepy.api.operations import send
from specklepy.objects import Base
from specklepy.transports.server import ServerTransport
# Create new Speckle type with pydantic
speckle_type = pydantic.create_model(
"TestClass",
__base__=Base,
__cls_kwargs__={"detachable": {"test"}},
**{"test": (str, None)})
# Create object of new Speckle type
test_object = speckle_type(test="test")
# Create Speckle client
client = SpeckleClient(host="https://speckle.xyz")
# Authenticate Speckle client
client.authenticate_with_token(token="YOURTOKEN")
# Initiate server transport
transport = ServerTransport(client=client, stream_id="7c1140bb24")
# Send object to server
obj_id = send(test_object, transports=[transport], use_default_cache=False)
# Create commit
client.commit.create(stream_id="7c1140bb24", object_id=obj_id, branch_name="main")
The issue is that this doesn’t work anymore since pydantic version 2.0. That is because pydantic has added an additional parameter __pydantic_reset_parent_namespace__ in their procedure to create a new class, see this line:
This results in a TypeError, as the additional argument cannot be handled by the __init_subclass__() method called from _RegisteringBase:
TypeError: TestClass.__init_subclass__() takes no keyword arguments
An ugly solution is to simply pop the additional parameter out during _RegisteringBase.__init_subclass__(), which does seem to work. Anyway, it doesn’t seem like a very proper solution, so I was hoping you can provide some help in this.
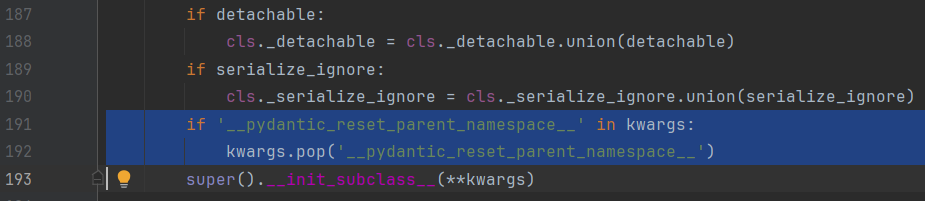
I have added you both to a stream where I tested the script above, with the additional change in the _RegisteringBase class:
Inefficient serialization
Another issue I dealt with is a very, very slow serialization for large objects. The structure that we send is particularly nested, for example with results that contain lots of structural elements, mesh, etc. This literally caused the serialization to run for hours, without actually finishing it. We do have detaching and chunking in place so that wasn’t the issue. The issue is that, due to the nested structure that we have, objects are being serialized and hashed over and over again, causing serious delays, or even unsuccessful sending of data.
Looking into your source code I was a bit surprised that the nested objects that have been serialized and/or even detached at an earlier stage are still being serialized and hashed again each time. I also noticed that for recompose_base(), you do have caching in place, with a simple deserialized dictionary that stores previously deserialized objects. I now did a very similar thing for the serialization procedure, which instead of running for hours without success now finishes in 1.5 minutes! I store the serialized objects based on their applicationId. Maybe this could be handled in a different way, but I definitely think there should be some kind of caching in place to drastically speed up the serialization of nested objects. Of course, if I’m overlooking an important reason against implementing such mechanism, I’d also be happy to hear. See the updated traverse_base() method here:
def _traverse_base(self, base: Base) -> Tuple[str, Dict]:
if not self.detach_lineage:
self.detach_lineage = [True]
# ADDED
# Return from cache if already traversed
if base.applicationId in self.serialized:
self.detach_lineage.pop()
return self.serialized[base.applicationId]
self.lineage.append(uuid4().hex)
object_builder = {"id": "", "speckle_type": "Base", "totalChildrenCount": 0}
object_builder.update(speckle_type=base.speckle_type)
obj, props = base, base.get_serializable_attributes()
while props:
prop = props.pop(0)
value = getattr(obj, prop, None)
chunkable = False
detach = False
# skip props marked to be ignored with "__" or "_"
if prop.startswith(("__", "_")):
continue
# don't prepopulate id as this will mess up hashing
if prop == "id":
continue
# only bother with chunking and detaching if there is a write transport
if self.write_transports:
dynamic_chunk_match = prop.startswith("@") and re.match(
r"^@\((\d*)\)", prop
)
if dynamic_chunk_match:
chunk_size = dynamic_chunk_match.groups()[0]
base._chunkable[prop] = (
int(chunk_size) if chunk_size else base._chunk_size_default
)
chunkable = prop in base._chunkable
detach = bool(
prop.startswith("@") or prop in base._detachable or chunkable
)
# 1. handle None and primitives (ints, floats, strings, and bools)
if value is None or isinstance(value, PRIMITIVES):
object_builder[prop] = value
continue
# NOTE: for dynamic props, this won't be re-serialised as an enum but as an int
if isinstance(value, Enum):
object_builder[prop] = value.value
continue
# 2. handle Base objects
elif isinstance(value, Base):
child_obj = self.traverse_value(value, detach=detach)
if detach and self.write_transports:
ref_id = child_obj["id"]
object_builder[prop] = self.detach_helper(ref_id=ref_id)
else:
object_builder[prop] = child_obj
# 3. handle chunkable props
elif chunkable and self.write_transports:
chunks = []
max_size = base._chunkable[prop]
chunk = DataChunk()
for count, item in enumerate(value):
if count and count % max_size == 0:
chunks.append(chunk)
chunk = DataChunk()
chunk.data.append(item)
chunks.append(chunk)
chunk_refs = []
for c in chunks:
self.detach_lineage.append(detach)
ref_id, _ = self._traverse_base(c)
ref_obj = self.detach_helper(ref_id=ref_id)
chunk_refs.append(ref_obj)
object_builder[prop] = chunk_refs
# 4. handle all other cases
else:
child_obj = self.traverse_value(value, detach)
object_builder[prop] = child_obj
closure = {}
# add closures & children count to the object
detached = self.detach_lineage.pop()
if self.lineage[-1] in self.family_tree:
closure = {
ref: depth - len(self.detach_lineage)
for ref, depth in self.family_tree[self.lineage[-1]].items()
}
object_builder["totalChildrenCount"] = len(closure)
obj_id = hash_obj(object_builder)
object_builder["id"] = obj_id
if closure:
object_builder["__closure"] = self.closure_table[obj_id] = closure
# write detached or root objects to transports
if detached and self.write_transports:
for t in self.write_transports:
t.save_object(id=obj_id, serialized_object=ujson.dumps(object_builder))
del self.lineage[-1]
# ADDED
# Add to cache
if obj.applicationId:
self.serialized[obj.applicationId] = obj_id, object_builder
return obj_id, object_builder
Let me know what you think about the topics!